ARM SIMD
ARM平台基于ARM v7-A架构的ARM Cortex-A系列处理器(Cortex-A5, Cortex-A7,Cortex-A8, Cortex-A9, Cortex-A15)上的NEON加速:
- 针对C/C++语言:循环展开等编译优化,-O2启用
- 针对NEON intrinsics:NEOM SIMD C/C++语言接口,针对架构启用V向量扩展,选择浮点处理器和ABI(application Binary Interface)接口类型
- 针对汇编语言:内联汇编,直接操作neon指令和寄存器 路线:了解相应编译优化=》使用intrinsic接口,学习对应汇编代码=》内联汇编,在编译器汇编代码基础上(否则可能反优化)学习并优化
references
算子源码
- AI算子:腾讯ncnn
- 数据处理算子:numpy simd
- 图像处理算子:Nvidia carotene,OpenCV third party
理论学习
指令流水线
经典的五级流水线模型

1、取指(IF)
- 以程序计数器(PC)中的内容作为地址,从存储器中取出指令并放入指令寄存器(IR);
- PC值加4(假设每条指令占4字节),指向顺序的下一条指令。
2、指令译码/读寄存器周期(ID)
- 对指令进行译码,并用IR中的寄存器地址去访问通用寄存器组,读出所需的操作数;
- 对IR中的立即数进行扩展
3、执行/有效地址计算周期(EX)
ALU对上一个周期中准备好的操作数进行运算或处理。在这个阶段,不同类型的指令进行的操作不同。
- (1)load和store指令:ALB把指令中所指定的寄存器的内容与偏移量相加,形成访存有效地址;
- (2)寄存器-寄存器 ALU 指令:ALU按照操作码指定的操作对从通用寄存器组中读出的数据进行运算;
- (3)寄存器-立即数 ALU 指令:ALU按照操作码指定的操作对从通用寄存器组中读出的操作数和指令中给出的立即数进行运算;
- (4)分支指令:ALU把指令中给出的偏移量与PC值相加,形成转移目标的地址。同时,对在前一个周期读出的操作数进行判断,确定分支是否成功。
4、存储器访问/分支完成周期(MEM)
- (1)load和store指令:load指令根据上一个周期计算出的有效地址从存储器中读出的相应的数据;store把指定的数据写入这个有效地址对应的存储单元。
- (2)分支指令:如果分支“成功”,就把前一个周期中计算好的转移目标地址送入PC。分支指令执行完成;否则,就不进行任何操作。
5、写回周期(WB)
- 把结果写入通用寄存器组。对于ALU运算来说,这个结果来自ALU,而对于load指令来说,这个结果来自存储器。
SIMD加速原理
- 《计算机体系结构:量化研究方法》。Neon是ARM平台的SIMD(Single Instruction Multiple Data,单指令多数据流)指令集实现,书中4.1~4.3讨论了SIMD,推荐阅读。

之所以能加速的原因总结:
- (1)通过加长的寄存器减少数据的读取/写入次数,从而减少将数据读入寄存器的时间开销。例如Neon可以一次性将16个int8(16*8=128bit)数据读入专用寄存器,这一次读取时间开销,明显少于16个int8数据一个一个地读入的时间之和。写入同理。(注意不要和cache的减少访存时间的原理混淆。从cache读取余下的第2~第16个int8数据到寄存器仍然是要花费时钟周期的)。
- (2)执行SISD(single instruction, Single data,单指令流单数据流,这里可理解为标量计算)指令时,需要完成(时间开销大的)冒险(hazard)检查。既然使用SIMD指令计算,就暗示这些数据之间无依赖性,也就从指令集层面回避了不必要的时间开销。
了解硬件决定的速度极限:Software Optimization Guide
我们可能还要关心,我们所编写的Neon Intrinsics,可以将手头上硬件的性能发挥到多少水平?是否还有提升空间?这些是好问题。
在讨论一个问题前,先插入一个使笔者拍案叫绝的相关案例:在另一本计算经典《深入理解计算机系统》 (一般简称 CS:APP)的第5章 优化程序性能 中,该书作者考虑若干计算机硬件特性,将矩阵乘法连续优化了6个版本,直至优化到了该x86 CPU的吞吐量上限(注:对于某种指令,延迟latency 主要关注单条该指令的最小执行时间,吞吐量throughout主要关注单位时间内系统(一个CPU核)最多执行多少条该指令。因为AI计算的数据量比较大,我们更关注吞吐量)
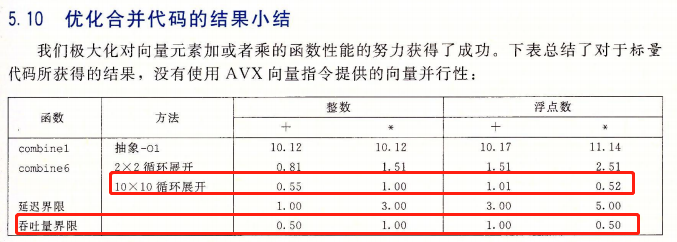
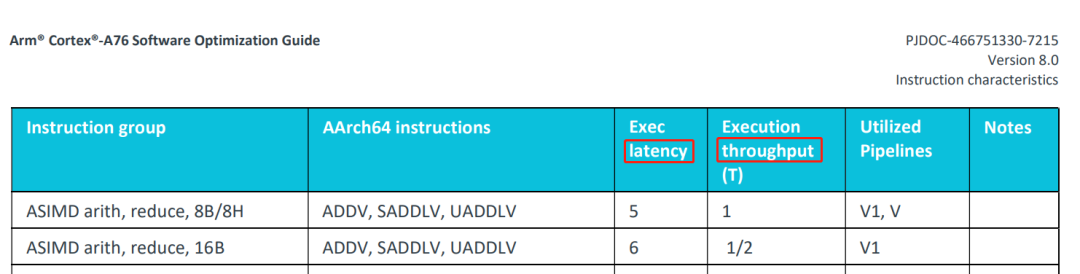
回到问题,我们需要知道我们的吞吐量上界是多少。ARM官方为每个CPU架构(手机CPU一般大核是A7X架构,小核是A5X架构)提供对应的Software Optimization Guide,里面有进行各种运算的latency和throughout。以A76架构(采用该架构作为大核架构的CPU例如骁龙855,麒麟980)为例子,从ARM官网下载对应的pdf(https://developer.arm.com/documentation/swog307215/a/?lang=en)
翻到ASIMD(Advance SIMD)那里,就能查阅各条Neon指令相应的latency和throughout。不同架构的吞吐量上界会有所不同,其他架构请自行在ARM官网文档中心下载。
理论数据有了,至于如何通过实验测试峰值,可参考BBuf的文章 如何判断算法是否有可优化空间? (https://zhuanlan.zhihu.com/p/268925243)
反汇编分析生成代码质量
可通过反汇编的方式查看Intrinsics 生成的汇编是否满足预期,如果不满足预期则进行手写汇编优化。具体操作可参考梁德澎的文章 移动端arm cpu优化学习笔记第4弹–内联汇编入门(https://zhuanlan.zhihu.com/p/143328317)
materials
- (1)研讨会视频 “Performance Analysis for Optimizing Embedded Deep Learning Inference Software,” a Presentation from Arm - Edge AI and Vision Alliance,建立优化分析思维
- (2)研讨会视频 LCU14-504: Taming ARMv8 NEON: from theory to benchmark results
- (3)研讨会视频 HKG15-408: ARM v8-A NEON optimization
- (4)Ne10(ARM官方的计算库):https://github.com/projectNe10/Ne10
- (5)Arm Optimized Routines(ARM官方的计算、网络、字符串库):https://github.com/ARM-software/optimized-routines
- (6)Neon优化Chromium的案例:https://developer.arm.com/documentation/101964/developer.arm.com
NEON 介绍
ARM NEON 是 ARM 架构的一种 SIMD(Single Instruction, Multiple Data)扩展,旨在加速多媒体、数字信号处理(DSP)、图像处理、音视频编解码、加密算法等高并发计算任务。NEON 是 ARMv7 (ARMv7-A只支持单精度,32x64-bit寄存器;Armv8-A AArch64支持双精度,32x128-bit寄存器,针对浮点操作的Vector Floating Point,VFP)及之后版本的处理器的标准扩展,广泛用于智能手机、嵌入式设备、平板电脑以及其他移动设备中,尤其是处理需要并行化的计算密集型应用时,它能显著提高性能。
重要概念
- lane:如一个
float32x4_t类型的变量float32x4_t v = {1.0f, 2.0f, 3.0f, 4.0f},它占用 128 位,存储 4 个 32 位的浮点数,在这个向量寄存器 v 中,每个值依次存储在不同的lane序号为0、1、2、3中。
NEON 寄存器
- 定义:NEON 使用专门的寄存器来存储向量数据,这些寄存器通常用于处理多个数据元素,ARMv7-A只支持单精度,32x64-bit寄存器;Armv8-A AArch64支持双精度,32x128-bit寄存器。
- 作用:NEON 寄存器组包含了 128 (Q字母)或 64(D字母) 位宽的寄存器,可以存储多个 8 位、16 位、32 位、64 位整数或浮点数据。
- 例子:
- Q0-Q15:128 位宽的 NEON 寄存器,用于存储 8 位、16 位、32 位、64 位的数据(整数或浮点数)。
- D0-D15:64 位宽的 NEON 寄存器,也用于存储 64 位数据。
向量和标量操作
- 定义:NEON 支持对向量(多个元素)和标量(单个元素)进行操作。
- 作用:标量操作是普通的逐元素操作,而向量操作则允许一次性处理多个数据元素。
- 例子:
vadd.f32:向量浮点加法操作。vadd.i32:向量整数加法操作。
NEON 数据类型
- 定义:NEON 支持多种数据类型,包括整数、浮点数、双精度浮点数和混合类型数据。
- 作用:不同的数据类型适应不同的应用需求,如 8 位整数、32 位浮点数等。
- 例子:
- i8, i16, i32, i64:不同宽度的整数类型。
- f32, f64:浮点数类型,支持单精度和双精度浮点数。
NEON 指令集
- 定义:NEON 提供了一组专门的指令来处理数据并执行并行计算。NEON 指令包括加法、乘法、减法、移位、汇聚(归约)、比较、选择、数据类型转换等。
- 作用:这些指令能够加速处理向量数据,尤其是应用于图像处理、音频处理、视频编解码、加密算法等领域。
- 例子:
- vadd:向量加法指令。
- vmul:向量乘法指令。
- vsub:向量减法指令。
- vmax:向量最大值选择指令。
扩展数据类型
- 定义:NEON 提供了扩展数据类型的支持,如高/低16位扩展、饱和算术、向量数据类型转换等。
- 作用:这种扩展数据类型用于在计算过程中执行高效的数据操作和转换,避免数据溢出或精度丢失。
- 例子:
- vshl:向左移位操作。
- vqadd:饱和加法指令,防止数据溢出。
数据载入和存储指令
- 定义:NEON 提供了一些专门的加载(load)和存储(store)指令,用于从内存中加载数据到寄存器,或将寄存器中的数据存储回内存。
- 作用:这些指令能够优化内存访问,支持从多个内存地址加载和存储数据。
- 例子:
vld1:加载向量数据指令。vst1:存储向量数据指令。
数据汇聚和归约操作
- 定义:NEON 提供了对向量数据的汇聚(归约)操作,例如求和、最大值、最小值等。
- 作用:这些操作通常用于计算总和、平均值、最大值等统计量,广泛应用于信号处理和数据分析中。
- 例子:
- vaddv:对向量元素进行加法归约,返回所有元素的和。
- vmaxv:对向量元素进行最大值归约,返回最大值。
条件执行
- 定义:NEON 支持条件执行,通过设置条件码(flags),可以对某些指令的执行进行条件限制。
- 作用:可以根据特定的条件执行指令,避免不必要的计算,提高性能。
- 例子:
vsel:根据掩码(mask)选择性地执行指令。
SIMD 聚合指令(广播操作)
- 定义:NEON 支持广播操作,允许单一标量值扩展到整个向量中。广播操作使得标量与向量的数据处理更加简便。
- 作用:通过广播操作,标量可以与向量中的每个元素进行计算,提高了指令的灵活性。
- 例子:
vdup:将一个标量值复制到整个向量中。
NEON 浮点数运算
- 定义:NEON 支持单精度浮点数和双精度浮点数的运算,符合 IEEE 754 标准。
- 作用:这些浮点数运算指令可用于科学计算、图像处理等应用。
- 例子:
- vadd.f32:单精度浮点数向量加法。
- vmul.f32:单精度浮点数向量乘法。
数据类型转换
- 定义:NEON 支持多种类型之间的转换操作,如浮点与整数类型之间的转换。
- 作用:这种转换对于不同数据类型之间的运算非常重要,可以确保类型匹配并避免数据丢失。
- 例子:
- vcvt.f32.s32:将 32 位整数转换为 32 位单精度浮点数。
- vcvt.s32.f32:将 32 位单精度浮点数转换为 32 位整数。
向量掩码
- 定义:NEON 支持通过掩码控制哪些向量元素应该被操作。掩码机制允许在处理多个数据时根据特定条件选择性地操作某些元素。
- 作用:掩码可以控制并行操作的粒度,提高计算的灵活性。
- 例子:
- vmla:向量乘加指令,根据掩码控制哪些元素参与计算。
NEON Intrinsic
兼容armv7和v8(部分指令可能不兼容),所以不同架构之间迁移方便,不需要改代码
References
- NEON-Intrinsics
- Neon Programmer Guide for Armv8-A Coding for Neon
- intrinsics检索,用来查看接口和支持架构
- ARM Neon Intrinsics 学习指北:从入门、进阶到学个通透
- numpy simd
数据和计算指令类型的格式
1、向量数据类型格式:<type><size>x<number of lanes>_t
- 比如
float32x4_t,=float, =32, =4
向量数据类型:

2、向量数组类型:<type><size>x<number of lanes>x<length of array>_t
- 比如
|
|
向量指令格式:<opname><flags>_<type>
- 比如
vmulq_f32,=vmul, =q, =f32
Note
- 普通计算逻辑考虑优化编译器优化、类型量化等
- 循环一般用do-while的形式
- 对于非整数倍元素个数的解决方法: leftovers
- 使用 NEON 的广播操作,避免显示复制数据
- 使用 NEON 的饱和操作,避免数据溢出
- 利用数据类型转换操作,并合理进行量化
- 利用shift、insert、mask等
计算机组成结构运行相关(通用)
并行
- 充分利用计算机流水线:去除数据依赖
- 逻辑操作代替分支选择(分支预测)
- 数据预加载(预取/并行)
资源利用
- 充分利用寄存器资源,分块处理数据,但避免寄存器溢出(Register Spilling)(测试时开启O2优化使编译器允许寄存器存储临时变量)
- 内存合理对齐分配,按对应寄存器长度读取
- 多线程处理,如OpenMP(并行/数据共享)
- 利用数据连续特性、利用cache
NEON 汇编
可用__aarch64__宏区分是armv8,否则armv7,针对性编写代码
References
arm 内联汇编使用
|
|
Note
- 先写intrinsic代码反汇编,学习编译器优化后的汇编代码,再优化
- 重点关注指令流水线排布,避免CPU的Hazard