介绍
CUDA(Compute Unified Device Architecture,统⼀计算架构)是由 NVIDIA 开发的并行计算平台和编程模型,旨在利用 NVIDIA GPU(图形处理单元)强大的并行计算能力来加速计算密集型任务。CUDA 提供了一种编程接口,让程序员能够直接访问 GPU 上的计算资源。通过并行化计算任务,可以显著提升执行效率。GPU 相较于 CPU,在处理大量并行任务时具有显著的优势,通常拥有成百上千的处理核心(CUDA 核心),能够同时执行大量的操作。
- 核心指标:核心数、GPU显存容量、GPU计算峰值、显存带宽
- GPU不能单独计算,CPU+GPU组成异构计算架构:CPU起到控制作用,一般称为主机(Host);GPU可以看作CPU的协处理器,一般称为设备(Device);主机和设备之间内存访问一般通过PCIe总线链接。
- CUDA 提供两层API接口:CUDA驱动(driver)API和CUDA运行时(runtime)API
CUDA驱动(driver)API
- cuda driver使用方式:libcuda.so和cuda.h,cuda-driver-api
- context管理机制:方便管理device
-
- 手动管理的context,cuCtxCreate(手动管理,以堆栈方式push/pop)
-
- 自动管理的context,cuDevicePrimaryCtxRetain(自动管理,runtime api以此为基础)
-
- 首先需要调用culnit初始化驱动API
CUDA运行时(runtime)API
- cuda runtime使用方式:libcudart.so和cuda_runtime.h。runtime API随cuda toolkit发布
- 主要内容:核函数的使用、线程束布局、内存模型、流的使用
- 主要实现:归约求和、仿射变换、矩阵乘法、模型后处理
References
- 《CUDA 并行程序设计-GPU 编程指南》 第5、6、9章
- https://github.com/loveleaves/ML_CPP/tree/main/ParallelFramework/CUDA
- cuda docs、programming-guide、best-practices-guide
- CIS 5650-GPU Programming and Architecture
- CUDA笔记
- CUDALibrarySamples
CUDA框架
基础编程框架
单文件example.cu编程框架
|
|
编译指令
|
|
nvcc编译工作原理
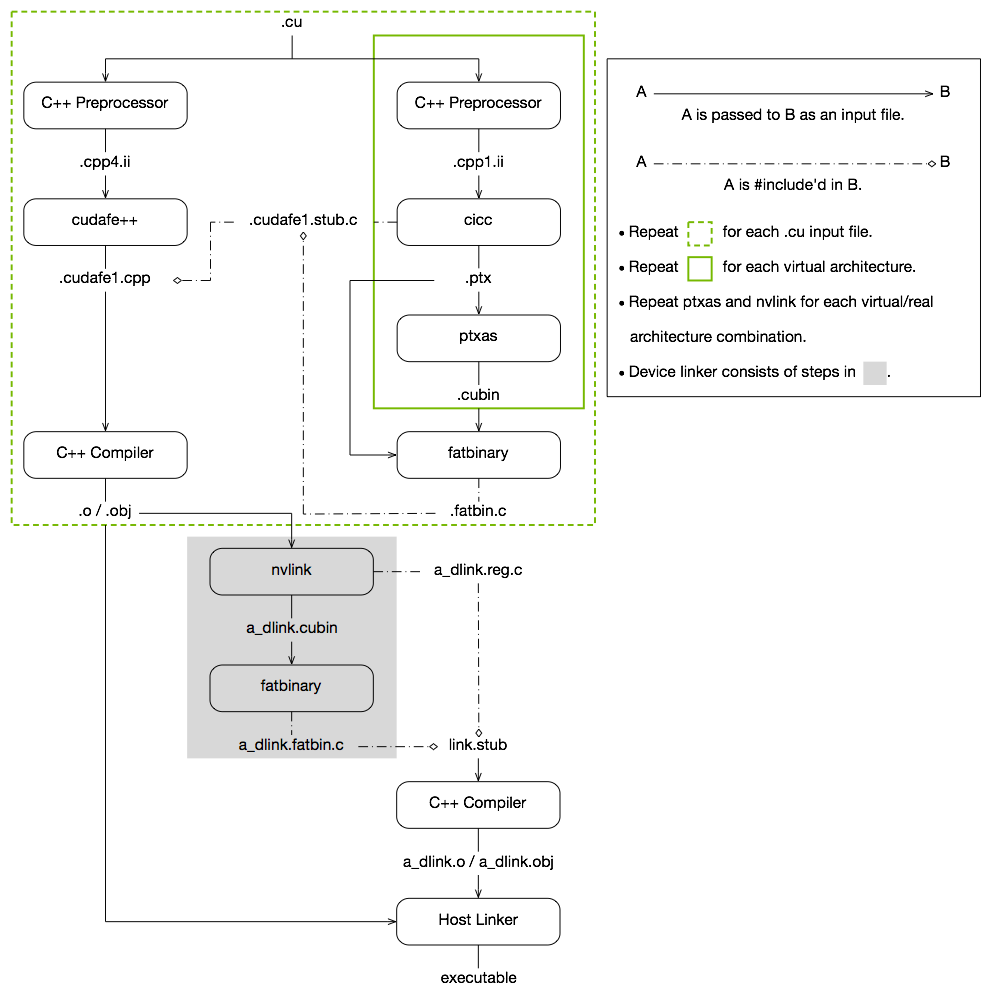
- host code(standard C/C++ compiler)、device code(compiled into PTX/cubin)
- CUDA程序兼容性考虑:在将源代码编译为 PTX 代码时,需要用选项-arch=compute_XY指定一个虚拟架构的计算能力,用以确定代码中能够使用的CUDA功能。在将PTX代码编译为cubin代码时,需要用选项-code=sm_ZW指定一个真实架构的计算能力,用以确定可执行文件能够使用的GPU。
- https://docs.nvidia.com/cuda/cuda-compiler-driver-nvcc/index.html
- Deep Dive into Triton Internals
GPU设备设置
- 1、获取GPU设备数量
|
|
- 2、设置GPU执行时使用的设备
|
|
内存管理
主设内存管理 Note:GPU内存管理runtime接口传入的是双重指针。
- 内存分配:malloc、cudaMalloc
- 数据传递:memcpy、cudaMemcpy
- 内存初始化:memset、cudaMemset
- 内存释放:free、cudaFree
主设内存传递
|
|
枚举类型kind可取值:
- cudaMemcpyHostToHost,表示从主机复制到主机。
- cudaMemcpyHostToDevice,表示从主机复制到设备。
- cudaMemcpyDeviceToHost,表示从设备复制到主机。
- cudaMemcpyDeviceToDevice,表示从设备复制到设备。
- cudaMemcpyDefault,表示根据指针dst和src所指地址自动判断数据传输的方向。这要求系统具有统一虚拟寻址(unifiedvirtualaddressing)的功能(要求64位的主机)。
数据同步Synchronize
- 调用输出函数时,输出流是先存放在缓冲区的,而缓冲区不会自动刷新。只有程序遇到某种同步操作时缓冲区才会刷新。所以当要打印某个数据时,要先使用函数cudaDeviceSynchronize显式地同步主机与设备,促使缓冲区刷新。
核函数(Kernel function)
- 1、核函数在GPU上进行并行执行
- 2、注意:
- (1)限定词__global__ 修饰(可在void前后)
- (2)返回值必须是void
- (3)对于N是非blockSize整数倍时,必要时添加if,即使导致条件分支
注意事项:
- 1、核函数只能访问GPU内存
- 2、核函数不能使用变长参数
- 3、核函数不能使用静态变量
- 4、核函数不能使用函数指针
- 5、核函数具有异步性
- 6、其他:核函数不支持C++的iostream
自定义设备函数
- 用__global__修饰的函数称为核函数,一般由主机调用,在设备中执行。如果使用动态并行,则也可以在核函数中调用自己或其他核函数。
- 用__device__修饰的函数叫称为设备函数,只能被核函数或其他设备函数调用,在设备中执行。
- 用__host__修饰的函数就是主机端的普通C++函数,在主机中被调用,在主机中执行。对于主机端的函数,该修饰符可省略。之所以提供这样一个修饰符,是因为有时可以用__host__和__device__同时修饰一个函数,使得该函数既是一个C++中的普通函数,又是一个设备函数。这样做可以减少冗余代码。编译器将针对主机和设备分别编译该函数。
- 不能同时用__device__和__global__修饰一个函数,即不能将一个函数同时定义为设备函数和核函数。
- 也不能同时用__host__和__global__修饰一个函数,即不能将一个函数同时定义为主机函数和核函数。
线程模型
- 线程的组织结构是由执行配置(executionconfiguration)«<grid_size,block_size»>决定的。这里的grid_size(网格大小)和block_size(线程块大小),对应核函数内部的内建变量 gridDim、blockDim、blockIdx、threadIdx
- 注意GPU系列对应框架最大允许的线程块大小,如1024
- 线程束:线程调度、管理
CUDA错误检查
运行时错误检测
所有CUDA运行时API函数都是以cuda为前缀的,而且都有一个类型为cudaError_t的返回值,代表了一种错误信息。只有返回值为cudaSuccess时才代表成功地调用了API函数。
功能正确性检查
- 内存检查、越界访问、异常检查等
- checktool
获得GPU加速的关键
CUDA事件计时
|
|
程序性能分析
Nsight Compute,详见tools
影响GPU加速的关键因素
- 数据传输的比例:主设数据传输
- 算术强度(arithmeticintensity):计算相比于数据传输耗时的占比
- 并行规模:数据规模要尽量匹配SM等计算资源
因此, 在编写与优化CUDA程序时,一定要想方设法(主要是指仔细设计算法)做到以下几点
- 减少主机与设备之间的数据传输。
- 提高核函数的算术强度。
- 增大核函数的并行规模。
CUDA中的数学函数库
- 单精度浮点数内建函数和数学函数(singleprecisionintrinsics and math functions)。使用该类函数时不需要包含任何额外的头文件。
- 双精度浮点数内建函数和数学函数(doubleprecisionintrinsicsandmathfunctions)。使用该类函数时不需要包含任何额外的头文件。
- 半精度浮点数内建函数和数学函数(halfprecisionintrinsicsandmathfunctions)。使用该类函数时需要包含头文件<cuda_fp16.h>。
- 整数类型的内建函数(integerintrinsics)。使用该类函数时不需要包含任何额外的头文件。
- 类型转换内建函数(typecasting intrinsics)。使用该类函数时不需要包含任何额外的头文件。
- 单指令-多数据内建函数(SIMDintrinsics)。使用该类函数时不需要包含任何额外的头文件。
内存组织
分层思想,平衡成本和效率(在编码中体现为高内聚、低耦合)

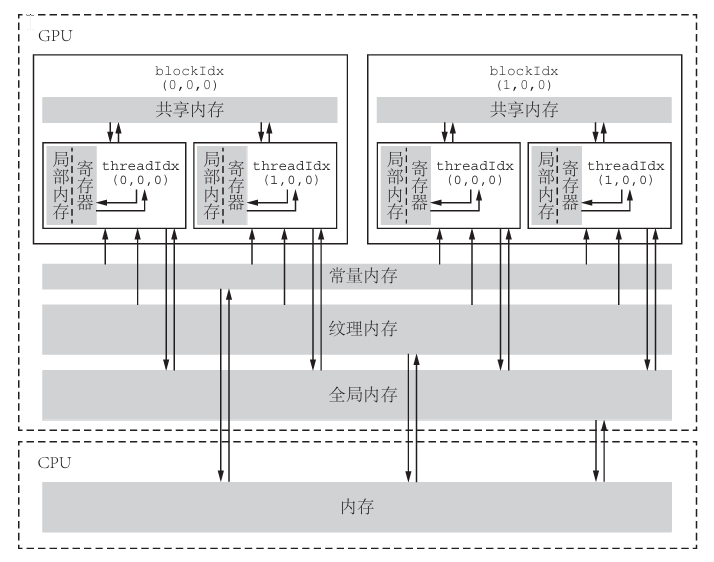
- https://docs.nvidia.com/cuda/cuda-c-programming-guide/index.html#device-variable-specifier
- 不同硬件架构的内存编排不一定相同
全局内存(global memory)
- 核函数中的所有线程都能够访问其中的数据,容量是所有设备内存中最大的。基本上就是显存容量。
- 主要为核函数提供数据,并在主机与设备及设备与设备之间传递数据。
- host端访问数据:使用runtime接口
cudaGetSymbolAddress() / cudaGetSymbolSize() / cudaMemcpyToSymbol() / cudaMemcpyFromSymbol() - 同步函数
__syncthreads():只是针对同一个线程块中的线程的,不同线程块中线程的执行次序依然是不确定的(不同线程块数据要保证不依赖)。 - 在CUDA中还有一种内部构造对用户不透明的(nottransparent)全局内存,称为CUDAArray。CUDAArray使用英伟达公司不对用户公开的数据排列方式,专为纹理拾取服务。
动态全局内存
- 生命周期(lifetime)不是由核函数决定的,而是由主机端决定的(cudaMalloc、cudaFree)
静态全局内存
- 静态全局内存变量由以下方式在任何函数外部定义:
|
|
- 在核函数中,可直接对静态全局内存变量进行访问,并不需要将它们以参数的形式传给核函数。
常量内存(constant memory)
- 有常量缓存的全局内存,一共仅有64KB,位于常量内存空间,核函数外部用
__constant__定义。 - 它的可见范围和生命周期与全局内存一样,host端访问数据与全局内存一样。 由于有缓存,常量内存的访问速度比全局内存高,但得到高访问速度的前提是一个线程束中的线程(一个线程块中相邻的32个线程)要读取相同的常量内存数据。
纹理内存(texture memory)和表面内存(surface memory)
- 类似于常量内存,也是一种具有缓存的全局内存,有相同的可见范围和生命周期,而且一般仅可读(表面内存也可写)。不同的是,纹理内存和表面内存容量更大,而且使用方式和常量内存也不一样。
- 对于计算能力5.0以上的GPU来说,将某些只读全局内存数据用
__ldg()函数通过只读数据缓存(read-onlydatacache)读取,既可达到使用纹理内存的加速效果,又可使代码简洁。对帕斯卡架构和更高的架构来说,全局内存的读取在默认情况下就利用了__ldg()函数,所以不需要明显地使用它。
寄存器(register)和 局部内存(local memory)
- 存储函数入参、内建变量和临时变量等,32位。
- 计算能力5.0~9.0的GPU,每个中都是64K的寄存器数量,Fermi架构只有32K;
- 考虑:每个线程块使用的最大数量、每个线程的最大寄存器数量
- 局部内存是全局内存的一部分,寄存器溢出是保存在局部内存中。
共享内存(shared memory)
- 和寄存器类似,存在于芯片上,具有仅次于寄存器的读写速度,
extern __shared__ float shared[]定义,数组大小在运行时确定,或__shared__ float shared[100]。 - 共享内存对整个线程块可见,其生命周期也与整个线程块一致。
- 一个线程块中的所有线程都可以访问该线程块的共享内存变量副本,但是不能访问其他线程块的共享内存变量副本。
- 注意避免n路bank冲突(n很大场景,类似TLB组相联):共享内存在物理上被分为32个(刚好等于一个线程束中的线程数目,即内建变量warpSize的值)同样宽度的、能被同时访问的内存bank。在所有其他架构中,每个bank的宽度为4字节。当同一线程束内的多个线程不同时访问同一个bank中不同层的数据,该线程束对共享内存的访问就只需要一次内存事务(memory transaction),就会发生bank冲突。
L1 和 L2 缓存
- 从费米架构开始,有了SM层次的L1缓存和设备(一个设备有多个SM)层次的L2缓存
SM及其占有率
SM(Streaming MultiProcessor)构成
一个GPU是由多个SM构成的。一个SM包含如下资源(不同架构不一定相同):
- 一定数量的寄存器。
- 一定数量的共享内存。
- 常量内存的缓存。
- 纹理和表面内存的缓存。
- L1缓存。
- 两个(计算能力6.0)或4个(其他计算能力)线程束调度器(warpscheduler),用于在不同线程的上下文之间迅速地切换,以及为准备就绪的线程束发出执行指令。
- 执行核心,包括:
- 若干整型数运算的核心(INT32)。
- 若干单精度浮点数运算的核心(FP32)。
- 若干双精度浮点数运算的核心(FP64)。
- 若干单精度浮点数超越函数(transcendentalfunctions)的特殊函数单元(Special Function Units,SFUs)。
- 若干混合精度的张量核心(tensorcores,由伏特架构引入,适用于机器学习中的低精度矩阵计算)。
SM管理
- GPU中每个SM都可以支持数百个线程并发执行
- 以线程块block为单位,向SM分配线程块,多个线程块可被同时分配到一个可用的SM上
- 当一个线程块被分配好后,就不可以在分配到其他上了
线程束(warp)
- CUDA 采用单指令多线程架构管理执行线程,每32个为一组,构成一个线程束。同一个线程块中相邻的 32个线程构成一个线程束
- 每个线程束中只能包含同一线程块中的线程
- 线程束是GPU硬件上真正的做到了并行
** SM 的占有率**
- 一般来说,要尽量让SM的占有率不小于某个值,比如%,才有可能获得较高的性能。
- SM的理论占有率(theoreticaloccupancy)的两个指标:
- 一个SM中最多能拥有的线程块个数
- 一个SM中最多能拥有的线程个数
- 根据寄存器、共享内存等具体架构具体分析
高效正确地并发并行
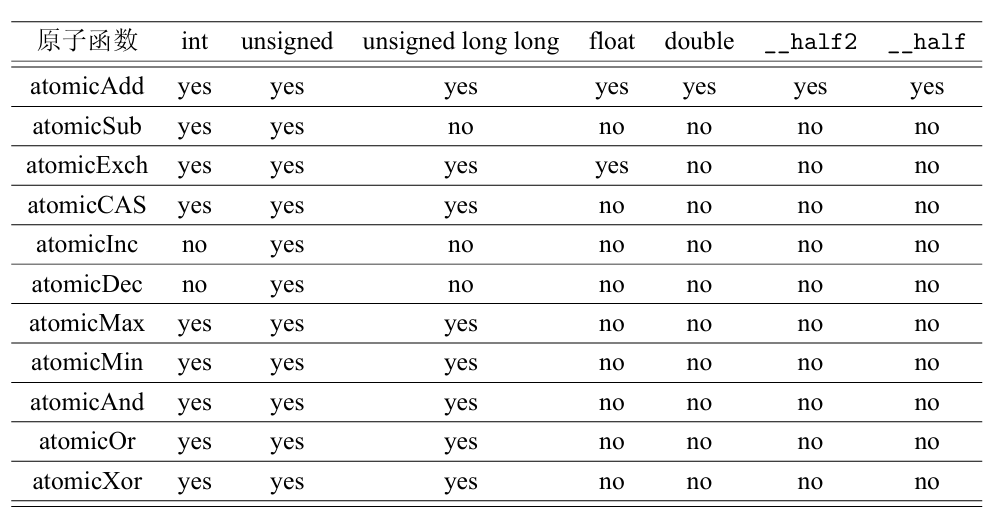
原子函数(atomic function)
cuda提供原子函数来进行控制数据一致性读写。其中atomicCAS函数是比较特殊的,所有其他原子函数都可以用它实现(指定架构不支持时,但性能可能较差)。
- Atomic APIs with
_systemsuffix (example:atomicAdd_system) are atomic at scopecuda::thread_scope_systemif they meet particular conditions. compute capability must greater than 7.2. - Atomic APIs without a suffix (example:
atomicAdd) are atomic at scopecuda::thread_scope_device. - Atomic APIs with
_blocksuffix (example:atomicAdd_block) are atomic at scopecuda::thread_scope_block.
线程束(warp)基本函数
- 一个SM以32个线程为单位产生、管理、调度、执行线程。这样的32 个线程称为一个线程束。
- SM执行属于单指令-多线程(single instruction, multiple thread,SIMT)的执行模式:在同一时刻,一个线程束中的线程只能执行一个共同的指令或者闲置。
- 在伏特架构之前,一个线程束中的线程拥有同一个程序计数器(programcounter),但各自有不同的寄存器状态(registerstate),从而可以根据程序的逻辑判断选择不同的分支。因此当同一个线程束(不同的不会)中的线程顺序地执行判断语句中的不同分支时,会发生分支发散(branch divergence)。
- 从伏特架构开始,引入了独立线程调度(independentthreadscheduling)机制。每个线程有自己的程序计数器。这使得伏特架构有了一些以前的架构所没有的新的线程束内同步与通信的模式,但导致:
- 增加了寄存器负担:单个线程的程序计数器一般需要使用两个寄存器。
- 独立线程调度机制使得假设了线程束同步(warpsynchronous)的代码变得不再安全:必须显式同步。
- 线程束内的线程同步函数:都在一个线程束内时,可以将线程块同步函数
__syncthreads换成一个更加廉价的线程束同步函数__syncwarp。 - 其他基本函数:
- 线程束表决函数(warpvotefunctions)
- 线程束匹配函数(warpmatchfunctions)
- 线程束洗牌函数(warp shuffle functions)
- 线程束矩阵函数(warp matrix functions)
协作组(cooperativegroups)
- 类似线程块和线程束同步机制的推广,它提供了更为灵活的线程协作方式,包括线程块内部的同步与协作、线程块之间的(网格级的)同步与协作及设备之间的同步与协作。
- https://docs.nvidia.com/cuda/cuda-c-programming-guide/index.html#introduction-cg
CUDA流(CUDA stream)
CUDA流介绍
主要用cuda流解决核函数外部的并行:
- 核函数计算与数据传输之间的并行。
- 主机计算与数据传输之间的并行。
- 不同的数据传输(回顾一下cudaMemcpy函数中的第4个参数)之间的并行。
- 核函数计算与主机计算之间的并行。
- 不同核函数之间的并行。
任何CUDA操作都存在于某个CUDA流中,要么是默认流(default stream),也称为空流(null stream),要么是明确指定的非空流。
- 在主机端产生与销毁。一个CUDA流由类型为cudaStream_t 的变量表示,
cudaStreamCreate和cudaStreamDestroy创建和销毁。 - 为了实现不同CUDA流之间的并发,主机在向某个CUDA流中发布一系列命令之后必须马上获得程序的控制权,不用等待该CUDA流中的命令在设备中执行完毕。这样,就可以通过主机产生多个相互独立的CUDA流。
- 检查一个CUDA流中的所有操作是否都在设备中执行完毕:
cudaStreamSynchronize同步、cudaStreamQuery查询
默认流(default stream)/ 为空流(null stream)
|
|
- 核函数的启动是异步的(asynchronous),或者说是非阻塞的(non-blocking),所以会host会立即执行下一条语句。该命令如果是CUDA操作不会被device立即执行,因为这是默认流中的CUDA操作,必须等待前一个CUDA操作(即核函数的调用)执行完毕才会开始执行。
- 可以在核函数启动后放置host操作,利用前面CUDA操作完成时间。
非默认流/非空流
|
|
用非默认CUDA流重叠核函数的执行与数据传递
- 要实现核函数执行与数据传输的并发(重叠),必须让这两个操作处于不同的非默认流,而且数据传输必须使用cudaMemcpy函数的异步版本,即
cudaMemcpyAsync函数。异步传输由GPU中的DMA(directmemoryaccess)直接实现,不需要主机参与。 - 在使用异步的数据传输函数时,需要将主机内存定义为不可分页内存(non-pageable memory)或者固定内存(pinned memory),在程序运行期间,其物理地址将保持不变,由
cudaMallocHost和cudaFreeHost申请和释放。
统一内存(unifiedmemory)编程
介绍
- 统一内存是一种逻辑上的概念,一种系统中的任何处理器(CPU或GPU)都可以访问,并能保证一致性的虚拟存储器。这种虚拟存储器是通过CPU和GPU各自内部集成的内存管理单元(memorymanagementunit)实现的。
- 使用统一内存对硬件有较高的要求:不低于开普勒架构等。
- 好处:不用手动内存传输管理;相比手动内存操作可能会有更好的性能;超量分配,类似虚拟内存策略。
基本使用
- 统一内存在设备中是当作全局内存使用的,而且必须在主机端定义或分配内存,而不能在设备端(核函数和
__device__函数)定义或分配内存。 - 动态申请:
cudaMallocManaged - 静态申请:
__device____managed__int ret[1000]; - 数据预取:
cudaMemPrefetchAsync
多GPU编程
CUDA标准库
cuda所以接口及库详见官网:cuda docs、cuda developer
Thrust
类似于C++的标准模板库(standard template library)
- thrust、NCCL
- 数据结构:容器
thrust::host_vector<typename>和thrust::device_vector<typename> - 算法:
-
- 变换(transformation)。本书多次讨论的数组求和计算就是一种变换操作。
-
- 规约(reduction)。这是本书重点讨论过的算法。
-
- 前缀和(prefixsum)。下一节将详细讨论该算法。
-
- 排序(sorting)与搜索(searching)。
-
- 选择性复制、替换、移除、分区等重排(reordering)操作。
-
cuBLAS(basic linear algebra subprograms)
基本线性代数子程序,矩阵在内存中的存储是列主序(column-major order)的Fortran 风格,而不是像C语言中是行主序(row-majororder)的。
- cublas、blas
- cuBLAS 库包含3个API:
- cuBLAS API:相关数据必须在设备。
- cuBLASXTAPI:相关数据必须在主机。
- cuBLASLt API:一个专门处理矩阵乘法的API。
cuFFT
快速傅里叶变换(fast Fourier transforms)
cuSPARSE
稀疏(sparse)矩阵
- cusparse
- cusparse提供了一些稀疏矩阵、向量和稠密矩阵、向量的运算函数。
cuSolver
稠密(dense)矩阵和稀疏(sparse)矩阵计算库
- cuSolver 专注于一些比较高级的线性代数方面的计算,如矩阵求逆和矩阵对角化,类似LAPACK库。基于cuBLAS和cuSPARSE两个更基础的库实现。
- cusolver、lapack
- cuSolver 库由以下3个相互独立的子库组成:
- cuSolverDN(DeNse, DN):一个处理稠密矩阵线性代数计算的库。
- cuSolverSP(SParse, SP):一个处理稀疏矩阵的线性代数计算的库。
- cuSolverRF(ReFactorization, RF):一个特殊的处理稀疏矩阵分解的库。
- cuSolver 库函数倾向于使用异步执行。为了保证一个cuSolver函数的工作已经完成,可以使用
cudaDeviceSynchronize()函数进行同步。
cuRAND
与随机数生成有关的库,包含伪随机数(pseudorandom numbers)和准随机数(quasirandom numbers)。
- curand
- cuRand是后向兼容(backward compatible)的,注意cuRAND 和 the CUDA runtime的版本对应
- 提供了两种API:主机API和设备API。
cuDNN
深度神经网络(deep neural networks)
- 是一个用于深度神经网络的 GPU 加速基元库。cuDNN 为标准例程(如前向和后向卷积、注意力、matmul、池化和规范化)提供高度优化的实现。
- cudnn docs、cudnn developer