References
介绍
OpenMP属于片上通信、跨核并行、共享存储式并行,支持跨平台共享内存方式的多线程编程接口(规范)。
OpenMP编程三要素
编译指导(Compiler Directive,19):包含并行域指令、工作共享指令、同步指令、数据环境
运行库函数(Runtime Library Routines,32)
环境变量(Environment Variables,9)
Note
OpenMP编程模型:内存共享模型,OpenMP是专为多处理器/核,共享内存机器所设计的。底层架构可以是UMA和NUMA。即(Uniform Memory Access和Non-Uniform Memory Access)
基于线程的并行性
显示的控制并行,极高的控制度
共享变量(默认),私有变量(通过private指定),数据竞争(Race Condition)(通过critical和atomic等同步机制)
CPU在主存上有L1、L2、L3多级缓存,L3为多核共有,但L1和L2为每个核心私有,所以存在缓存一致性问题(False Sharing)
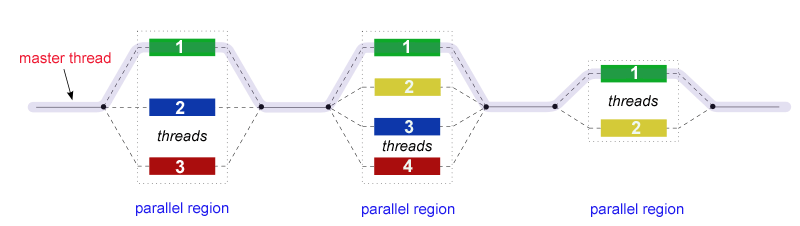
Fork-Join模型:以一个主线程开始,通过fork创建并行线程组,通过join同步合并只留下主线程。
使用
编译
1
2
3
4
#include <omp.h>
> gcc - fopenmp test . c
> export OMP_NUM_THREADS = n # 指定线程数量,omp_get_num_threads()获取
> ./ a . out
编译器指令
OpenMP编译器指令用于各种目的:
产生平行区域
在线程之间划分代码块
在线程之间分配循环迭代
序列化代码段
线程之间的工作同步
格式如下
#pragma omp <directive> [clause[[,] clause] ...]
通用规则:
区分大小写
指令遵循编译指令的C/C++规则
每个指令只能指定一个指令名
每个指令最多使用一个后续语句,该语句必须是结构化块
通过在指令行末尾用反斜杠(“\”)转义换行符,可以在后续行上“继续”长指令行
OpenMP基本指令
1、定义并行区域
#pragma omp parallel
用途 : 定义一个并行区域,启动多个线程并行执行该区域中的代码。
示例:
1
2
3
4
#pragma omp parallel
{
// 并行执行的部分
}
#pragma omp for
用途: 将循环的迭代分配给多个线程并行执行。
示例:
1
2
3
4
#pragma omp parallel for
for (int i = 0; i < n; i++) {
// 并行执行的循环体
}
#pragma omp single
用途:指定代码块只由第一个到达线程执行,其他线程跳过该代码块。
2、同步机制(Synchronization)
#pragma omp critical
用途: 定义一个临界区,保证代码块在同一时刻只被一个线程执行,以防止竞争条件。
1
2
3
4
5
6
7
8
9
10
11
12
13
float res;
#pragma omp parallel
{
float B;
int i, id, nthrds;
id = omp_get_thread_num0;
nthrds=omp_get_num_threads0;
for(i=id;i<niters;i+=nthrds){
B= big _job(i);
#pragma omp critical //Threads wait their turn. Only one at a time calls consume()
res += consume (B);
}
}
#pragma omp barrier
用途: 强制所有线程在此处同步,确保所有线程都执行到这一步后,才继续执行后续代码。
1
2
3
4
5
6
7
#pragma omp parallel
{
int id=omp_get_thread_num0;
A[id] = big_calc1 (id);
#pragma omp barrier // 只有当所有线程都到达barrier的时候才会继续运行
B[id] = big_calc2(id, A);
}
1
2
3
4
5
6
7
8
#pragma omp parallel
{
double tmp, B;
B= DOITO;
tmp = big ugly(B);
#pragma omp atomic
X+= tmp;
}
1
2
3
4
5
6
7
#pragma omp parallel
{
#pragma omp for
for(i=0;i<n;i++){ // i is private by default
do...;
}
}
3、变量的作用域
shared:默认情况下,并行区域外申明的变量在并行区域中是共享的,可以使用shared子句显式指定变量为共享的。
示例:
1
2
3
4
5
int a;
#pragma omp parallel for shared(a)
for (int i = 0; i < n; i++) {
// a为公有变量
}
private:每个线程在并行区域中有自己独立的变量副本,线程之间相互独立,互不干扰。并行区域内申明的变量默认为私有的,并行区域外申明的变量需要显式申明private
示例:
1
2
3
4
5
6
int a;
#pragma omp parallel for private(a)
for (int i = 0; i < n; i++) {
int b;
//a,b均为私有变量
}
reduction: 用于将每个线程的私有变量在并行区域结束时进行归约(如求和、求最大值等),最终将结果存储到共享变量中。
示例:
1
2
3
4
5
int sum = 0;
#pragma omp parallel for reduction(+:sum)
for (int i = 0; i < 10; i++) {
sum += i;
}
4、调度方法
static:静态调度将循环的迭代均匀分配给所有线程,并且相邻的迭代会被分配在同一个线程,分配方式在程序开始执行时就已经确定。
示例:
1
2
3
4
#pragma omp parallel for schedule(static, 3)
for (int i = 0; i < n; i++) {
// 每个线程执行3个连续的迭代
}
dynamic:动态调度在执行时分配迭代,每当一个线程完成当前分配的迭代时,它会动态获取下一个块的迭代。guided:引导调度是一种动态调度的变体,但块大小(chunk size)随着任务的完成而逐渐减小。auto:自动调度将调度策略的选择权交给编译器或运行时库,由它们决定最佳的调度方式。runtime:运行时调度允许在程序运行时通过环境变量设置调度策略。
环境变量
OMP_SCHEDULE:负责规定调度方式。
OMP_NUM_THREADS:设置执行期间要使用的最大线程数。
OMP_PROC_BIND:启用或禁用线程绑定到处理器。有效值为TRUE或FALSE。
OMP_STACKSIZE:控制创建(非主)线程的堆栈大小。
Licensed under CC BY-NC-SA 4.0
最后更新于 Feb 19, 2025 00:00 +0800