References
概念
什么是中间件?
非底层操作系统软件,非业务应用软件,不是直接给最终用户使用的,不能直接给客户带来价值的软件统称为中间件。
什么是消息中间件?
关注于数据的发送和接受,利用高效可靠的异步消息传递机制集成分布式系统。
消息中间件的作用(解耦,并发,削峰,异步)
- 可以在模块、服务、接口等不同粒度上实现解耦
- 订阅/消费模式可以在数据粒度上解耦
- 可提高系统的并发能力,集中力量办大事(同步部分),碎片时间做小时(异步部分)
- 可提高系统可用性,因为缓冲了系统负载
消息中间件的弊端
- 系统可用性降低:MQ宕机之后整套系统均不能正常使用,如果要保障队列可用,需要额外机制保障(双活或容灾)
- 系统复杂性提高:存在消息重复消费、消息丢失、消息传递顺序不能保证的问题
- 降低数据一致性:多个系统消费存在部分成功部分失败的问题,数据不一致了,如要保持强一致性,需要高代价的补偿(分布式事务,对账)
重复消费:系统发了两条,两条都插入了数据库 消息丢失:系统根本没法请求到目标系统 一致性问题:系统要再ABC三个系统都执行成功之后才返回成功,结果AB成功了,C失败了
什么是消息队列?(Message queue,简称MQ)
从字面理解就是一个保存消息的一个容器。那么我们为何需要这样一个容器呢?
其实就是为了解耦各个系统,我们来举个例子:
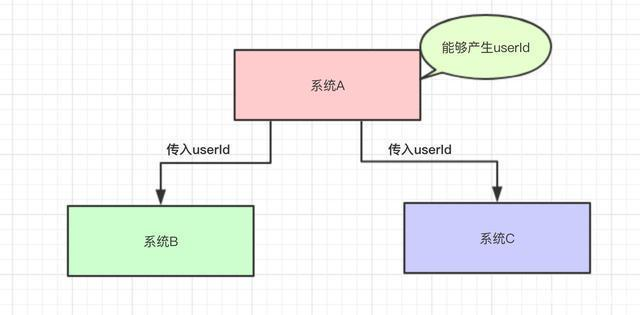
有这么一个简单的场景,系统A负责生成userID,并调用系统B、C。如果系统BC频繁变化是否需要userID参数,则系统A的代码就得不断变化,如果哪天又来了系统DEF……也需要这个参数,则系统A又要加入很多业务逻辑,这样子各他系统之间就容易产生相互影响,另外大量的系统与A发生交互也容易产生问题。
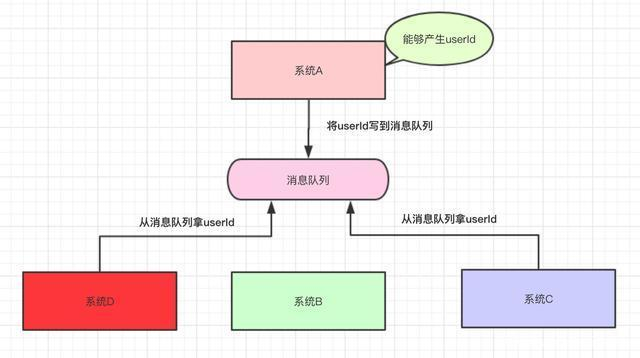
加了消息队列后,A只负责产生userID,至于谁要用这个参数,怎么用?系统A不管。对这个数据感兴趣的系统自己去取用即可,各个系统之间就实现了解耦。而且解耦后,整个服务业变成了一个异步的方式,系统A产生数据后,不用依次调用BCD来累计耗时,各系统可以同时来取用消息队列的数据进行处理,加大吞吐。
消息队列的特点
- 先进先出:消息队列的顺序在入队的时候就基本已经确定了,一般是不需人工干预的。
- 发布订阅:发布订阅是一种很高效的处理方式,如果不发生阻塞,基本可以当成是同步操作。
- 持久化:持久化确保消息队列的使用不只是一个部分场景的辅助工具,而是让消息队列能像数据库一样存储核心的数据。
- 分布式:在现在大流量、大数据的使用场景下,支持分布式的部署,才能被广泛使用。消息队列的定位就是一个高性能的中间件。
消息队列的使用场景
消息队列的使用场景有很多,最核心的有三个:解耦、异步、削峰
- 解耦:一个系统或者一个模块,调用了多个系统或者模块,相互之间的调用很复杂,维护起来很麻烦。此时可以考虑使用消息队列来实现多个系统之间的解耦
- 异步:系统A接受一个请求,需要在自己本地写库,还需要在系统BCD三个系统写库,同步操作比较费时。
- 削峰:高峰时段系统接收到的请求缓存到消息队列,供系统根据负载慢慢消化
如秒杀、发邮件、发短信、高并发订单等。 不适合的场景如银行转账、电信开户、第三方支付等。 关键还是要意识到队列的优劣点,然后分析场景是否使用。
其他使用场景还有:
- 最终一致性:先写消息再操作,例如预写日志(Write Ahead Log,WAL)
- 日志处理:比如 Kafka 的应用,解决海量日志传输和缓冲的问题。
- 消息通信:消息队列一般都内置了高效的通信机制
MQ的6种工作模式:
- 简单模式:一个生产者,一个消费者
- work模式:一个生产者,多个消费者,每个消费者获取到的消息唯一。
- 发布/订阅模式(Pub/Sub):一个生产者发送的消息会被多个消费者获取。
- 路由模式:发送消息到交换机并且要指定路由key ,消费者将队列绑定到交换机时需要指定路由key
- topic模式:将路由键和某模式进行匹配,此时队列需要绑定在一个模式上,“#”匹配一个词或多个词,“*”只匹配一个词。
消息队列常见问题
如何保证消息队列的高可用(High Available, HA)?
RabbitMQ基于主从的高可用,分为单机模式、普通集群模式、镜像集群模式三种
- 普通集群模式:多台服务器部署RabbitMQ,一个queue只会保存在一个节点上,其他节点只会同步该queue的元数据,当请求从其他节点获取该queue的数据时,该节点会再次去存储该queue的节点上拉取所需数据。这样就导致使用时要么固定使用其中一个节点,要么随机节点再需要的时候拉取数据。如果存放数据的节点宕机了,其他节点就无法拉取数据,如果开启了消息持久化让RabbitMQ落地存储消息就不一定会丢失消息,得等这个实例恢复后才能继续从这个queue拉取数据。
- 镜像集群模式(高可用模式):创建的queue会同步到所有实例上来实现高可用。这样会带来同步数据的开销和扩展性降低(扩展机器会导致新增的机器同步queue增加更多同步数据的开销);配置方式可通过控制台配置。
Kafka的高可用:分布式消息队列
Kafka由多个broker组成,每个broker是一个节点,创建的一个topic划分为多个partition,每个partition可放在不同的broker上,每个partition只存放一部分数据。