References
- tensorrt docs
- tensorrt api
- install tensorrt
- TensorRT samples
- Implementation of popular deep learning networks with TensorRT
TensorRT推理部署方案
C++硬代码方案
- 代表:tensorrtx
- 流程:C++硬代码=》TRT API =》 TRT Builder =》 TRT Engine
ONNX方案
- 流程:ONNX(libnvonnxparser.so) =》TRT API =》 TRT Builder =》 TRT Engine
- 一般思路:
- 导出模型onnx,查看输入和输出。
- 查看代码,找到onnx的预处理,分析预处理逻辑
- 利用上述信息实现onnx py推理实现
- 验证正常可实现转TRT模型用C++实现推理
TensorRT库文件
- libnvinfer.so:TensorRT核心库
- libnvinfer_plugin.so:nvidia官方提供的插件,github
- libprotobuf.so:protobuf库
- libnvonnxparser.so:ONNX解析
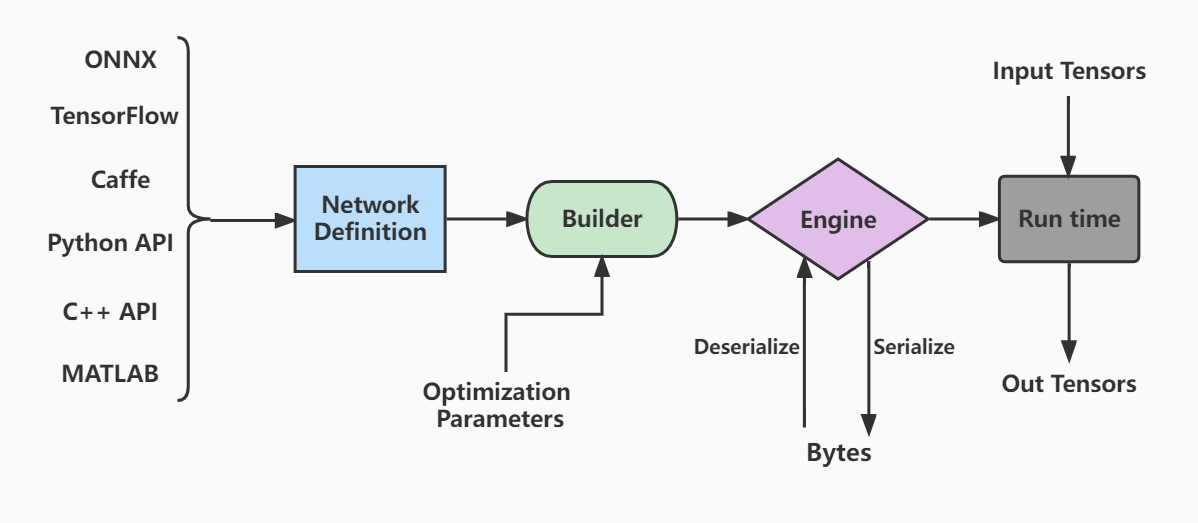
TensorRT部署推理模型流程
模型构建
- tensorrt的工作流程如下图:
- 首先定义网络
- 优化builder参数
- 通过builder生成engine,用于模型保存、推理等
- engine可以通过序列化和逆序列化转化模型数据类型(转化为二进制byte文件,加快传输速率),再进一步推动模型由输入张量到输出张量的推理。
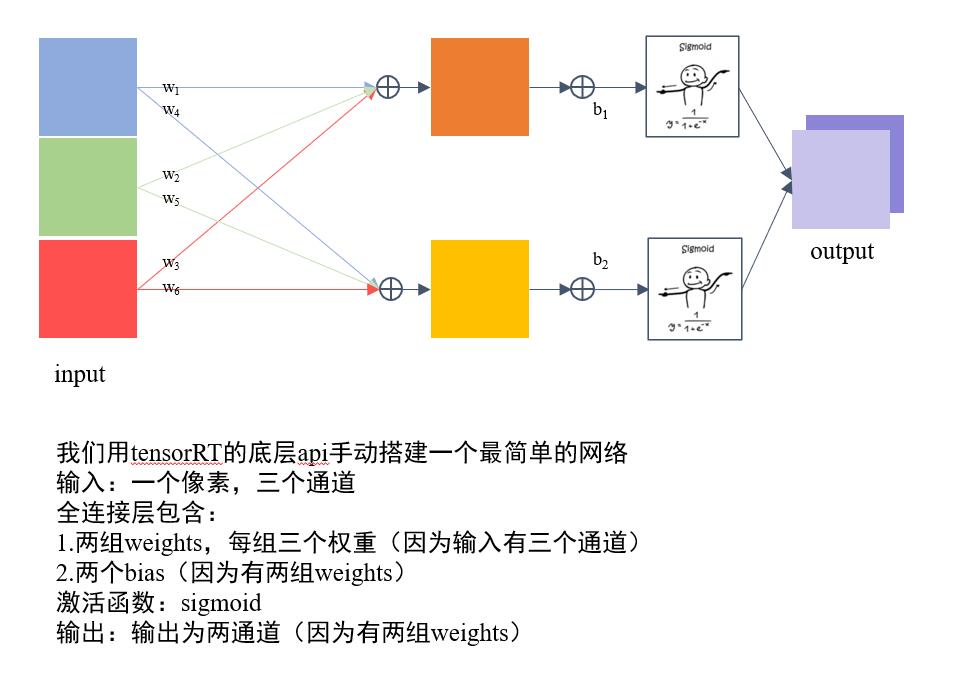
- code structure
- 定义 builder, config 和network,其中builder表示所创建的构建器,config表示创建的构建配置(指定TensorRT应该如何优化模型),network为创建的网络定义。
- 输入,模型结构和输出的基本信息(如下图所示)
- 生成engine模型文件
- 序列化模型文件并存储
模型推理
执行推理的步骤:
-
准备模型并加载
-
创建runtime:
createInferRuntime(logger) -
使用运行时时,以下步骤:
-
反序列化创建engine, 得为engine提供数据:
runtime->deserializeCudaEngine(modelData, modelSize),其中modelData包含的是input和output的名字,形状,大小和数据类型1 2 3 4 5 6class ModelData(object): INPUT_NAME = "data" INPUT_SHAPE = (1, 1, 28, 28) // [B, C, H, W] OUTPUT_NAME = "prob" OUTPUT_SIZE = 10 DTYPE = trt.float32 -
从engine创建执行上下文:
engine->createExecutionContext()
-
-
创建CUDA流
cudaStreamCreate(&stream):- CUDA编程流是组织异步工作的一种方式,创建流来确定batch推理的独立
- 为每个独立batch使用IExecutionContext(3.2中已经创建了),并为每个独立批次使用cudaStreamCreate创建CUDA流。
-
数据准备:
- 在host上声明
input数据和output数组大小,搬运到gpu上 - 要执行inference,必须用一个指针数组指定
input和output在gpu中的指针。 - 推理并将
output搬运回CPU
- 在host上声明
-
启动所有工作后,与所有流同步以等待结果:
cudaStreamSynchronize -
按照与创建相反的顺序释放内存
重要接口使用说明:
- TR10中的节点索引变更为字符串,之前是数值
- 必须使用createNetworkV2,并指定为1(表示显性batch)。createNetwork已经废弃,非显性batch官方不推荐。这个方式直接影响推理时enqueue还是enqueueV2(TR10为V3)
- builder、config等指针,记得释放,否则会有内存泄漏,使用ptr->destroy()(TR10使用delete)释放
- markOutput表示是该模型的输出节点,mark几次,就有几个输出,addlnput几次就有几个输入。这与推理时相呼应
- workspaceSize是工作空间大小,某些layer需要使用额外存储时,不会自己分配空间,而是为了内存复用,直接找tensorRT要workspace空间。
- bindings是tensorRT对输入输出张量的描述,
bindings = input-tensor + output-tensor。比如input有a, output有b,c, d,那么bindings = [a, b, c, d],bindings[0] = a, bindings[2] = c。此时看到engine- >getBindingDimensions(0)你得知道获取的是什么(TRT10改成了IOTensors) enqueueV2是异步推理,加入到stream队列等待执行。输入的bindings则是tensors的指针(注意是device pointer)。其shape对应于编译时指定的输入输出的shape(这里只演示全部shape静态)(TRT10使用enqueueV3)
动态shape
-
构建网络时:
- 1.1. 必须在模型定义时,输入维度给定为-1,否则该维度不会动态。注意一下两点:
- 1.1.1. 若onnx文件,则onnx文件打开后应该看到为动态或者-1
- 1.1.2. 如果你的模型中存在reshape类操作,那么reshape的参数必须随动态进行计算。而大部分时候这都是问题。除非你是全卷积模型,否则大部分时候只需要为batch_size维度设置为动态,其他维度尽量避免设置动态
- 1.2. 配置profile:
- 1.2.1. create:
builder->createOptimizationProfile() - 1.2.2. set:
setDimensions()设置kMIN,kOPT,kMAX的一系列输入尺寸范围 - 1.2.3. add:
config->addOptimizationProfile(profile);添加profile到网络配置中
- 1.2.1. create:
- 1.1. 必须在模型定义时,输入维度给定为-1,否则该维度不会动态。注意一下两点:
-
推理阶段时:
- 2.1. 您需要在选择profile的索引后设置
input维度:execution_context->setBindingDimensions(0, nvinfer1::Dims4(1, 1, 3, 3));(TR10为setInputShape)- 2.1.1. 关于profile索引:
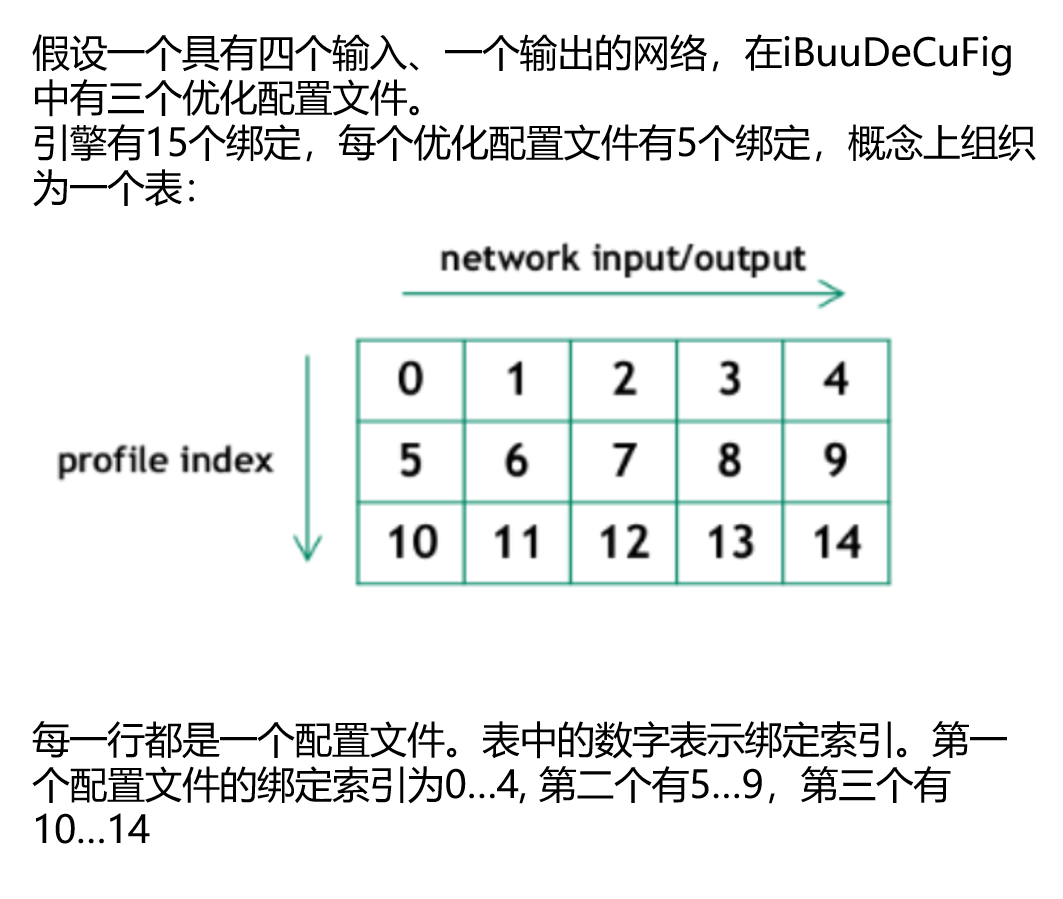
- 2.1.2. 在运行时,向engine请求绑定维度会返回用于构建网络的相同维度。这意味着,得到的还是动态的维度[-1, in_channel, -1, -1]:
获取当前的实际维度,需要查询执行上下文:
1 2engine.getBindingDimensions(0) // return [-1, 1, -1, -1] // execution_context->getTensorShape // TR10接口1context.getBindingDimensions(0) // return [3, 1, 3, 3]
- 2.1.1. 关于profile索引:
- 2.1. 您需要在选择profile的索引后设置
-
检查正确性
- 我们通常可以利用pytorch来校验是否发生了错误
ONNX模型操作
代码实战:
pytorch-gen-onnx.py:是之前讲过的从pytorch转换onnx格式的代码。- 通过
onnx-ml.proto和make-onnx-pb.sh了解onnx的结构- 2.1. onnx是基于protobuf来做数据存储和传输,*.proto后缀文件, 其定义是protobuf语法,类似json。
- 2.2. 对于变量结构、类型等,我们可以参照
onnx-ml.proto里面的定义。这个文件有800多行,放心我们只要搞清楚里面的核心部分就行:ModelProto:当加载了一个onnx后,会获得一个ModelProto。它包含一个GraphProto和一些版本,生产者的信息。GraphProto: 包含了四个repeated数组(可以用来存放N个相同类型的内容,key值为数字序列类型.)。这四个数组分别是node(NodeProto类型),input(ValueInfoProto类型),output(ValueInfoProto类型)和initializer(TensorProto类型);NodeProto: 存node,放了模型中所有的计算节点,语法结构如下:
ValueInfoProto: 存input,放了模型的输入节点。存output,放了模型中所有的输出节点;TensorProto: 存initializer,放了模型的所有权重参数AttributeProto:每个计算节点中还包含了一个AttributeProto数组,用来描述该节点的属性,比如Conv节点或者说卷积层的属性包含group,pad,strides等等;
- 2.3. 通过protoc编译
onnx-ml.proto,产生onnx-ml.pb.cc文件1bash make-onnx-pb.sh
- create-onnx.py
- 3.1. create-onnx.py直接从构建onnx,不经过任何框架的转换。通过import onnx和onnx.helper提供的make_node,make_graph,make_tensor等等接口我们可以轻易的完成一个ONNX模型的构建。
- 3.2. 需要完成对node,initializer,input,output,graph,model的填充
- 3.3. 读懂creat-onnx.py以make_node为例:

- edit-onnx.py
- 4.1. 由于protobuf任何支持的语言,我们可以使用[c/c++/python/java/c#等等]实现对onnx文件的读写操作
- 4.2. 掌握onnx和helper实现对onnx文件的各种编辑和修改
- 增:一般伴随增加node和tensor
1 2graph.initializer.append(xxx_tensor) graph.node.insert(0, xxx_node) - 删:
1graph.node.remove(xxx_node) - 改:
1input_node.name = 'data'
- 增:一般伴随增加node和tensor
- read-onnx.py
- 5.1 通过
graph可以访问参数,数据是以protobuf的格式存储的,因此当中的数值会以bytes的类型保存。需要用np.frombuffer方法还原成类型为float32的ndarray。注意还原出来的ndarray是只读的。
- 5.1 通过
ONNX Parser
onnx解析器有两个选项,
libnvonnxparser.so或者- onnx-tensorrt parser(源代码)。
- 使用源代码的目的,是为了更好的进行自定义封装,简化插件开发或者模型编译的过程,更加具有定制化,遇到问题可以调试
onnx-tensorrt parser代码使用:
- 什么是onnx:
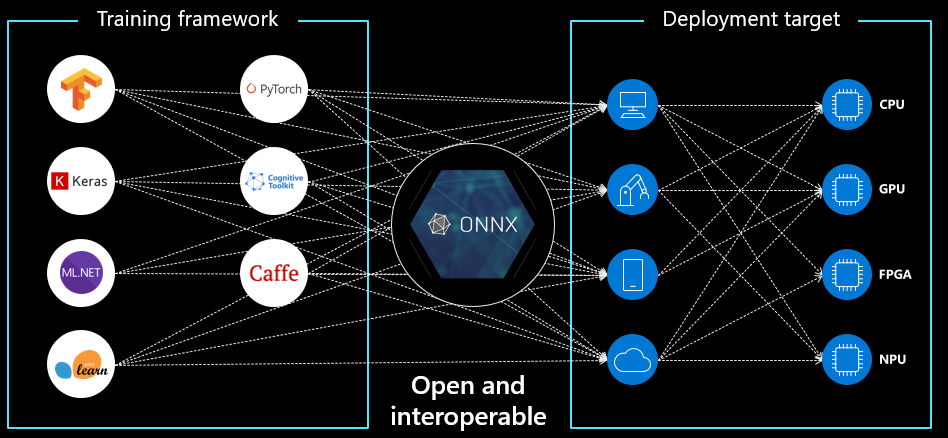
- 先看名字:Open Neural Network Exchange(ONNX) 是一个开放的生态系统,使代码不被局限在框架和平台中。
- 具体一点:onnx可以把你的神经网络模型(PyTroch, TF, Caffe)统统转为标准的ONNX格式(一种protobuf格式),然后就可在各种平台(云平台, windows, linux)和设备(cpu, gpu, npu)上运行
- 先看文件
gen-onnx.py以pytorch构建的模型为例讲:pytorch模型转onnx格式- 构建一个pytorch网络,并声明一个model对象
- 如果进行推理,将模型设为推理状态:这一点很重要,因为像dropout, batchnorm这样的算子在推理和训练模式下的行为是不同的。
- 导出为onnx模型:
torch.onnx.export() - 运行python脚本,生成onnx,在
main.cpp中会对其进行解析1python gen-onnx.py - 运行后的图示:
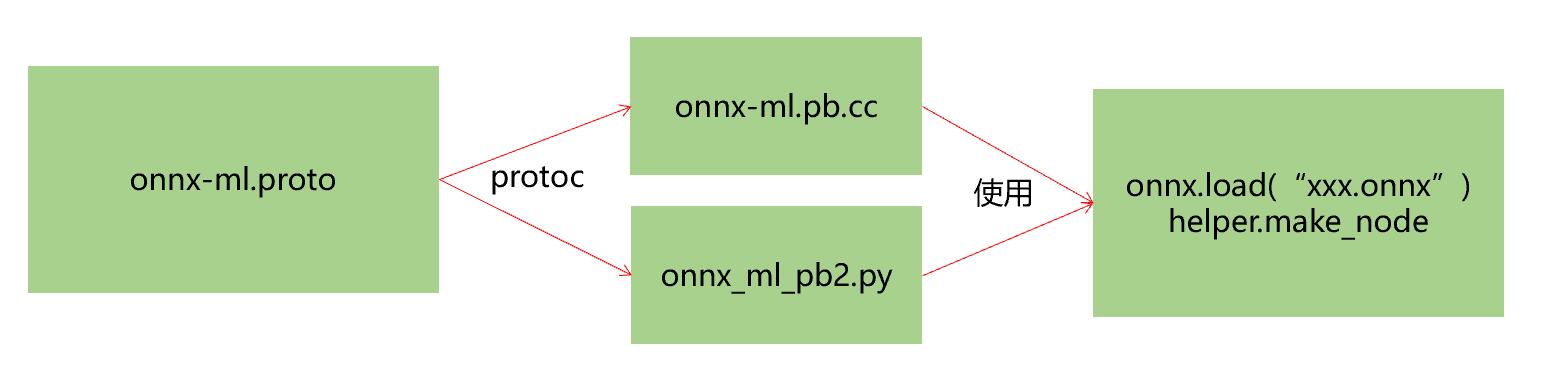
- Protobuf则通过onnx-ml.proto编译得到onnx-ml.pb.h和onnx-ml.pb.cc或onnx_ml_pb2.py
- 然后用onnx-ml.pb.cc和代码来操作onnx模型文件,实现增删改
- onnx-ml.proto则是描述onnx文件如何组成的,具有什么结构,他是操作onnx经常参照的东西
- 再看文件
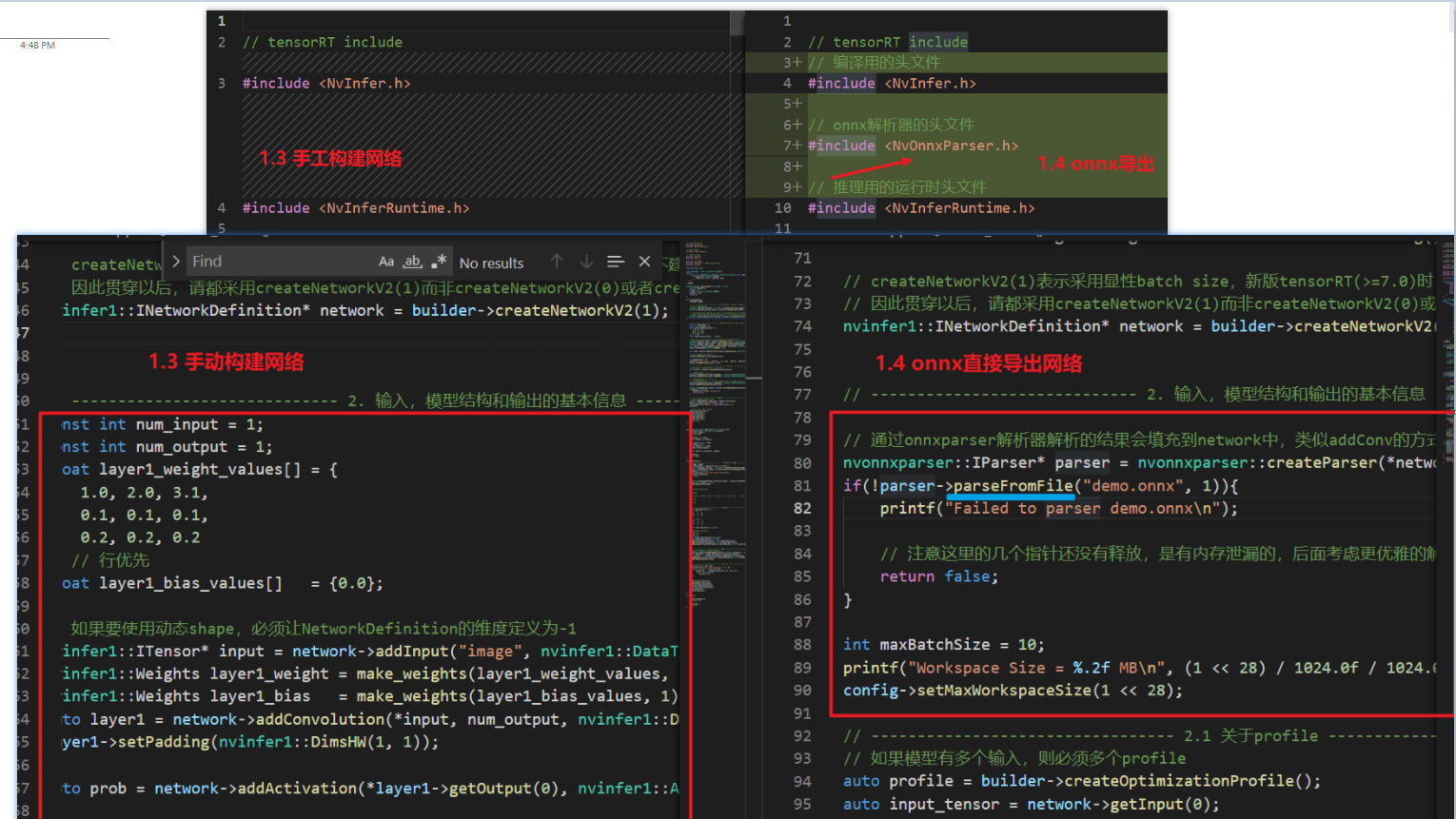
main.cpp讲解如何解析onnx格式- 使用onnx解析器:
createParser的api在文件NvOnnxParser.h中 - 在这里使用onnx的结果填充到network中,而手动构建网络则是将输入和算子填入network中,区别如图所示:
- 导出后,可以使用netron软件进行打开查看:https://github.com/lutzroeder/Netron
- 使用onnx解析器:
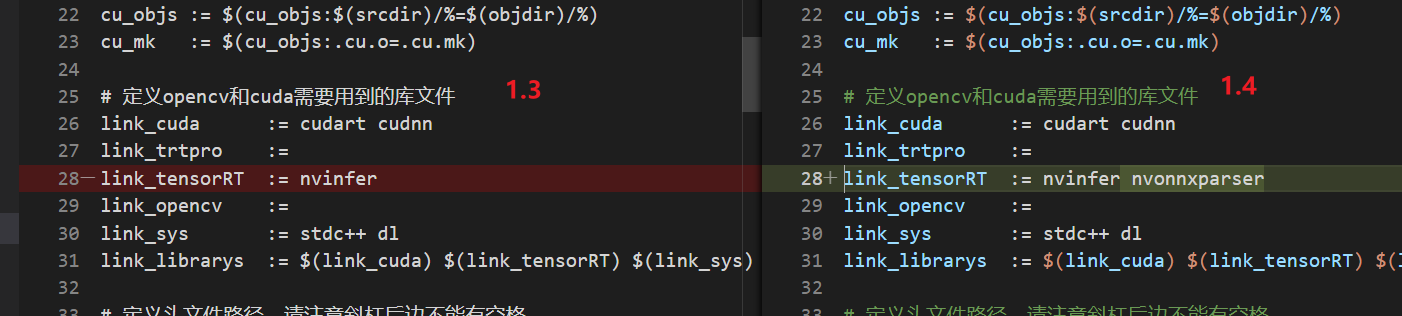
- 除了构建过程的区别,makefile中,库文件也需要加上nvonnxparser:
注意:
- severity_string 和 log仅是工具函数,无需过分关注
导出TRT模型
为了使用onnx导出网络有三种方式:
- 我们使用自带的解析器,
libnvonnxparser.so - 从源代码编译:onnx-tensorrt,主要protobuf文件:
- 利用官方工具
trtexec,YOLOv8部署推理案例 Usage:
|
|
Plugin
1.如何在pytorch里面导出一个插件 2.插件解析时如何对应,在onnx parser中如何处理 3.插件的creator实现 4.插件的具体实现,继承自IPluginV2DynamicExt 5.插件的序列化与反序列化
量化
int8量化
- 对于int8,需要配置setFlag nvinfer1::BuilderFlag::kINT8,并且配置setInt8Calibrator
- 对于Int8EntropyCalibrator,则需要继承自IInt8EntropyCalibrator2
- Int8EntropyCalibrator的作用,是读取并预处理图像数据作为输入
- 标定的原理,是通过输入标定图像I,使用参数WInt8推理得到输出结果PInt8,然后不断调整WInt8,使得输出PInt8与PFloat32越接近越好
- 因此标定时通常需要使用一些图像,正常发布时,一般使用100张图左右即可
- 常用的Calibrator
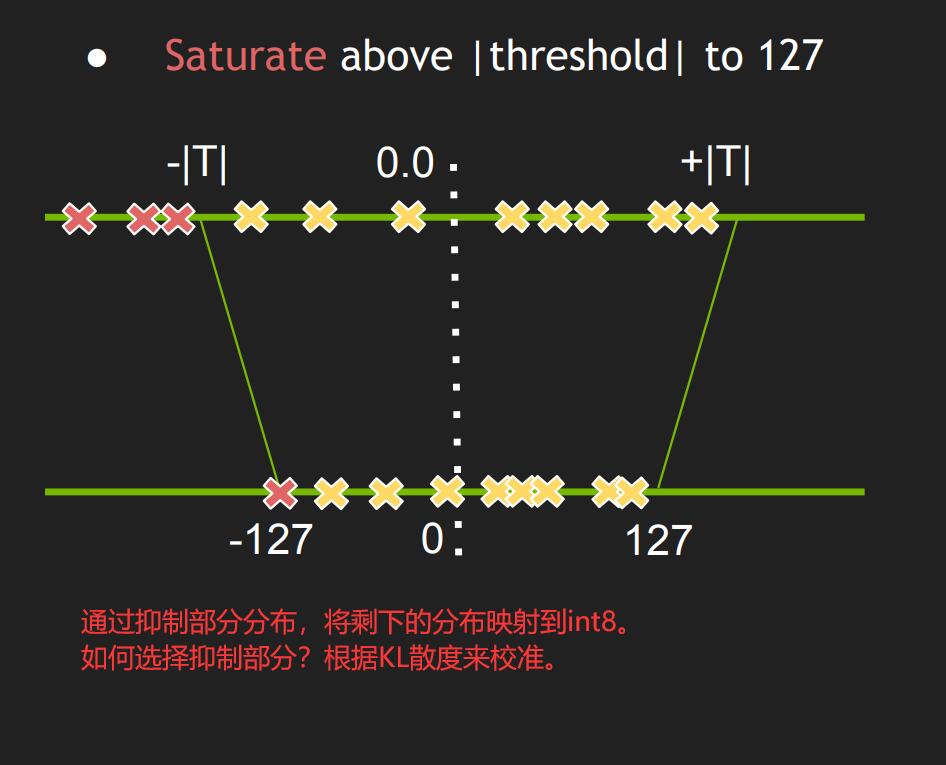
- Int8EntropyCalibrator2
熵校准选择张量的比例因子来优化量化张量的信息论内容,通常会抑制分布中的异常值。这是当前推荐的熵校准器。默认情况下,校准发生在图层融合之前。推荐用于基于 CNN 的网络。
- Iint8MinMaxCalibrator
该校准器使用激活分布的整个范围来确定比例因子。它似乎更适合NLP任务。默认情况下,校准发生在图层融合之前。推荐用于NVIDIA BERT等网络。
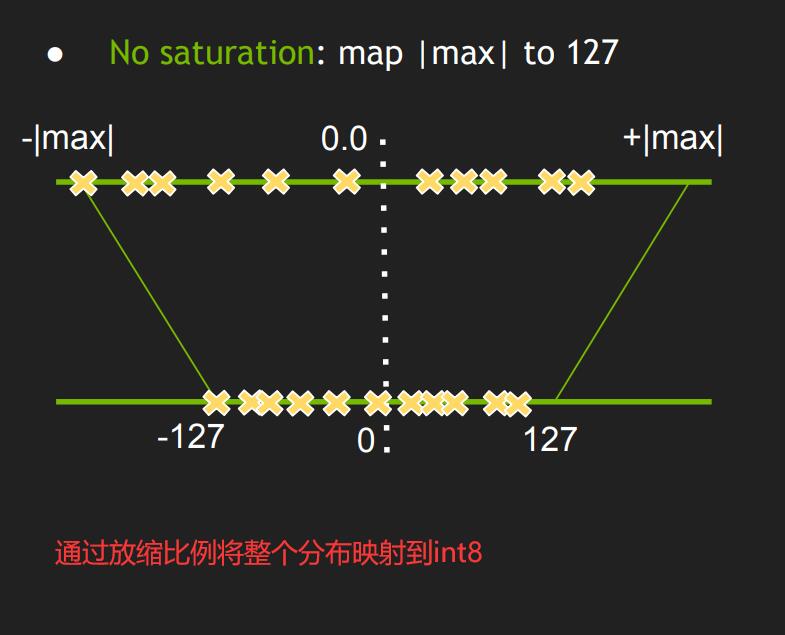
- Int8EntropyCalibrator2
熵校准选择张量的比例因子来优化量化张量的信息论内容,通常会抑制分布中的异常值。这是当前推荐的熵校准器。默认情况下,校准发生在图层融合之前。推荐用于基于 CNN 的网络。
- 计算机中的float计算量是非常大的,而改成int8后,计算量相比可以提升数倍
- 对于实际操作时,input[float32], w[int8], bias[float32], output[float32]
- 步骤如下:
- input[int8] = to_int8(input[float32])
- y[int16] = input[int8] * w[int8] # 此处乘法会由计算机转换为int16,保证精度
- output[float32] = to_float32(y[int16]) + bias[float32]
- 所以整个过程的只是为了减少float32的乘法数量以实现提速
- 对于to_int8的过程,并不是直接的线性缩放,而是经过KL散度计算最合适的截断点(最大、最小值),进而进行缩放,使得权重的分布尽可能小的被改变
- 可以参照这个地址:https://on-demand.gputechconf.com/gtc/2017/presentation/s7310-8-bit-inference-with-tensorrt.pdf