References
- Int8量化-介绍
- 量化方法汇总
- 从TensorRT与ncnn看CNN卷积神经网络int8量化算法
- 谷歌量化白皮书:Quantizing deep convolutional networks for efficient inference: A whitepaper、Quantization and Training of Neural Networks for Efficient Integer-Arithmetic-Only Inference
- ppq
- 神经网络 - 量化与部署
- 模型压缩:模型量化打怪升级之路 - 1 工具篇
神经网络加速基础知识
计算机体系结构/组成原理
主要了解以下部分:
指令耗时/热点指令

现代处理器
经典CPU体系结构
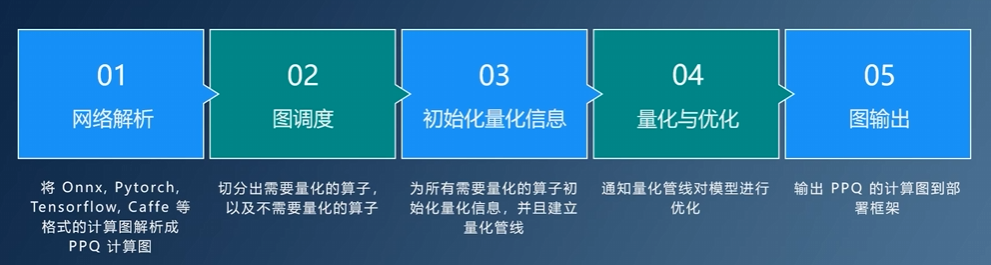
x86架构(CISC)
- 胶水typo,多核心
- 部分组件公共化,提高集成度
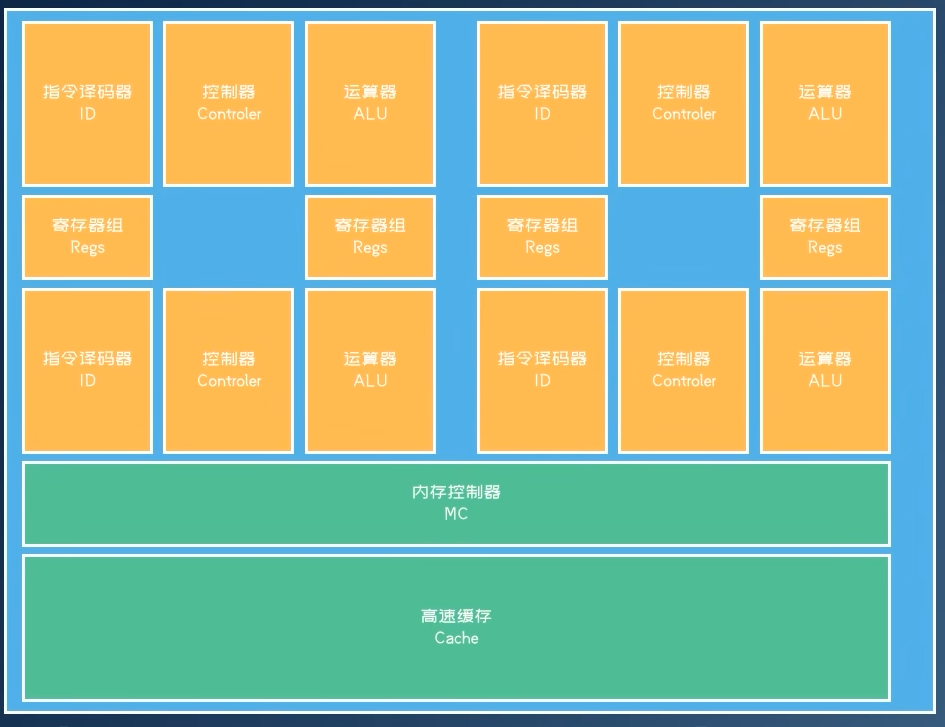
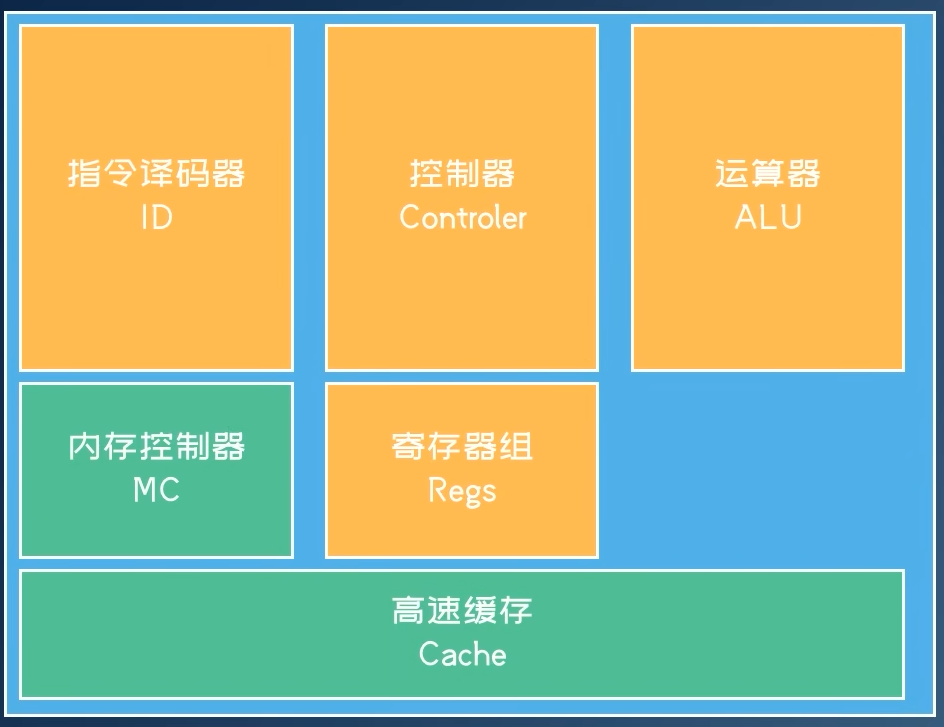
GPU架构
- 共享指令译码和控制,ALU运行的指令相同(分支发散问题)
- GPU架构介绍
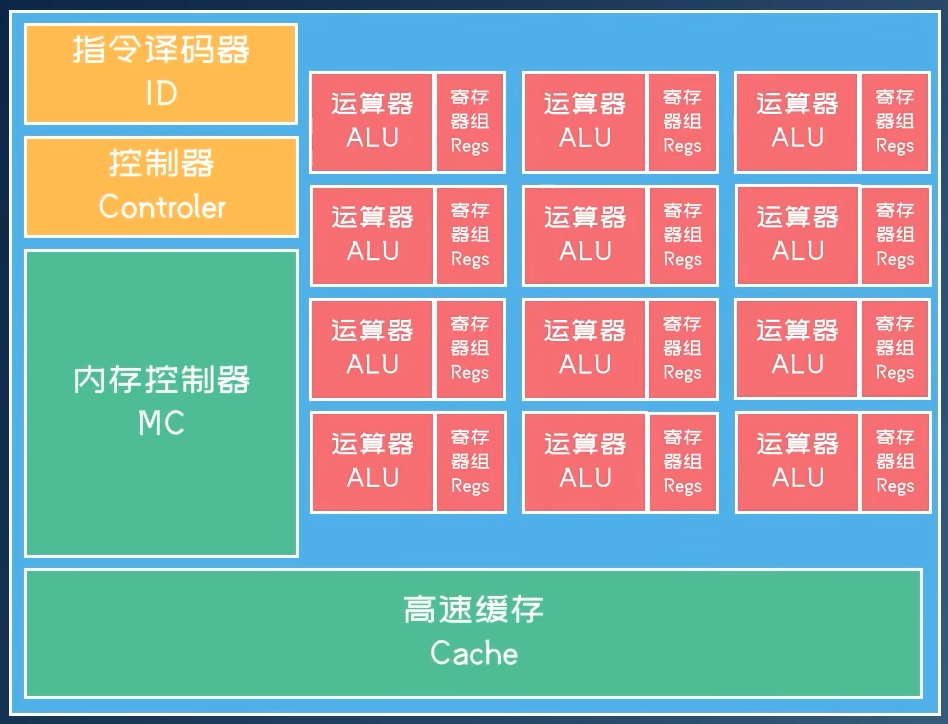
ASIC专用芯片架构
- 继续移除非必要指令(浮点、图形支持等)
- 特定领域设计
异构计算与主从设备交互

找到性能瓶颈(performance bottleneck)
- 高算力场景=》用ASIC等芯片,提高算力,高延迟
- 低延迟场景=》用FPGA等芯片,降低延迟,低算力
性能热点分析工具
torch Profiler
Nsight Compute
量化硬件实现
量化算子
基本公式:
|
|
取整函数round_fn比较特别,在不同硬件上有不同的取整模式(主要对中间值,如1.5,-2.5等),常见取整模式:
- Round half to even,torch 、 C使用,向偶数方向取整
- Round half away from zero,向正负无穷方向取整
- Round half toward zero,向0方向取整
- Round half down,向下取整
- Round half up,向上取整
量化子图与全精度子图(quantized subgraph)
权重是可以直接计算出来的,推理的时候只要计算一下量化算子即可
-
通常情况,量化算子全部支持场景:
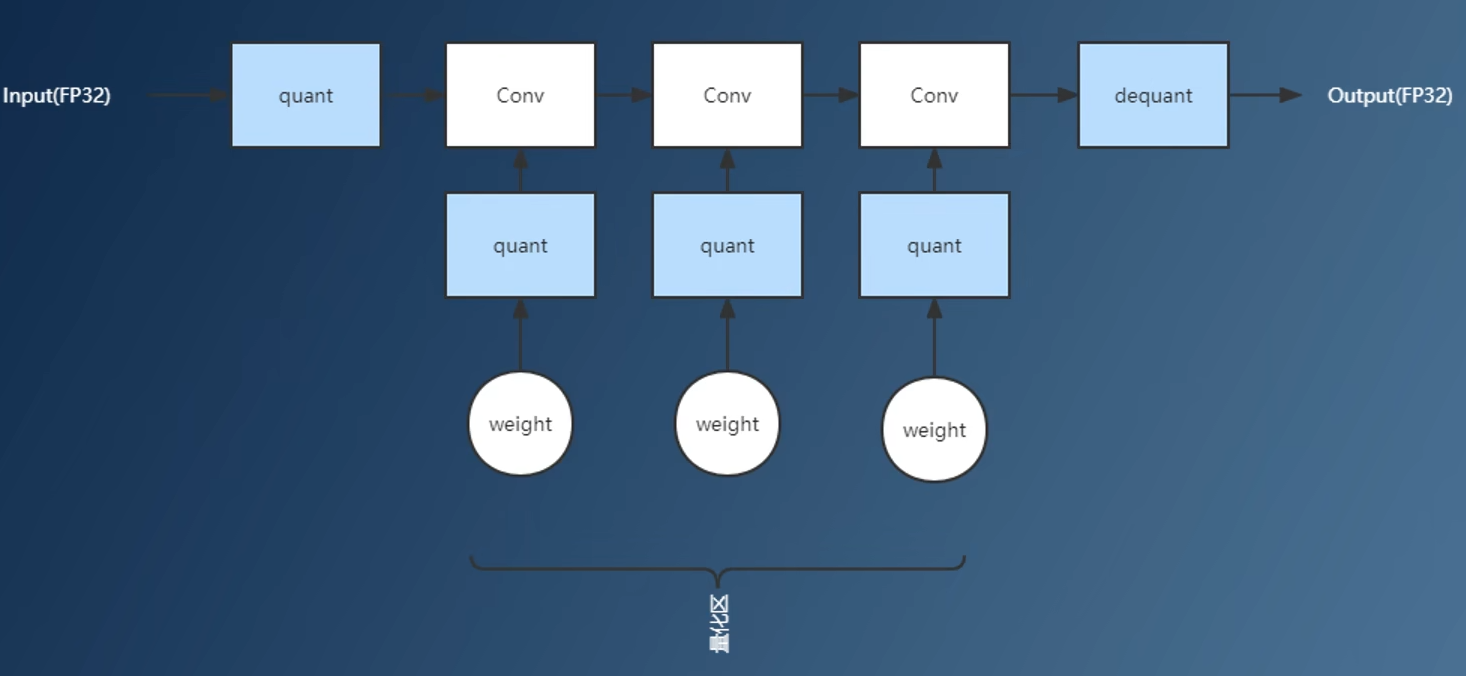
-
存在不支持量化算子,可用
子图分割分离不支持运算子图分开计算,但会导致访存开销为热点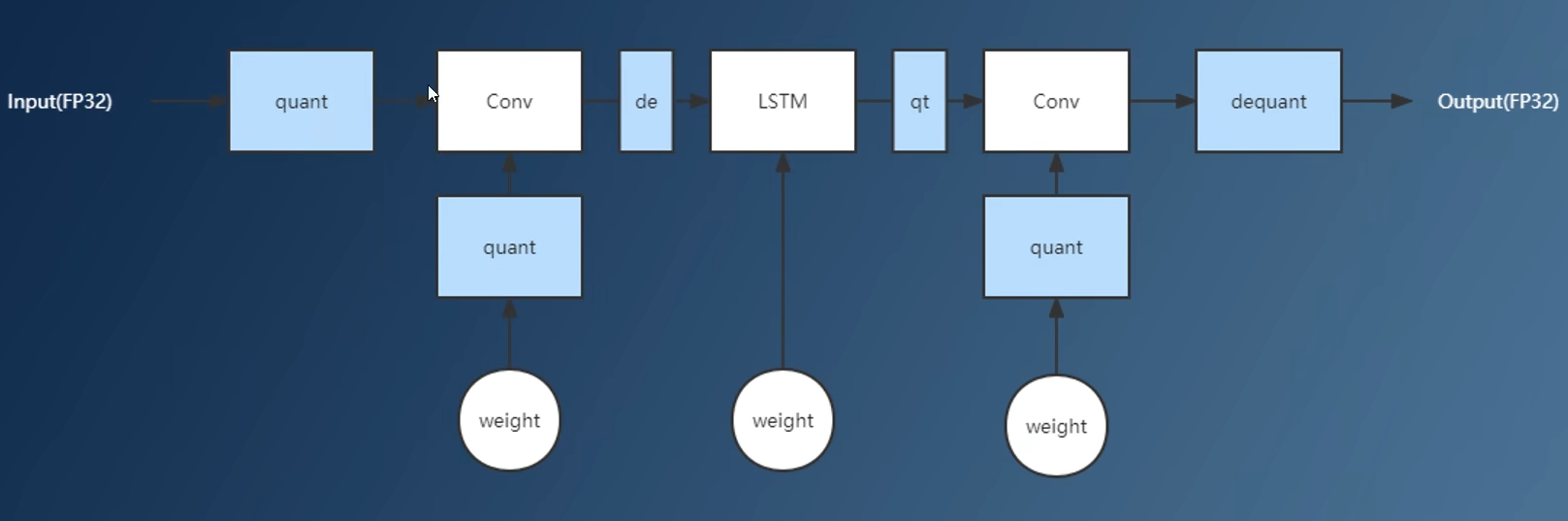
反量化算子
基本公式:
|
|
量化模式(量化与反量化)
- 对称量化:基本量化模式,分布对称
|
|
- 非对称量化:充分利用int8数值范围(如relu负数范围)
|
|
- 整数量化(power of two):部分硬件不支持浮点运算,用整数运算替换
|
|
- 指数量化…
tensor量化与通道量化
以上对称/非对称量化、整数量化中的offset、shift可以整个数据为粒度进行量化(可能数值偏差大,量化差),也可以采用其他粒度进行量化:
- tensor量化(per-tensor):以单个tensor为粒度
- 通道量化(per-channel):以单个channel为粒度
量化计算怎么写
- 整数运算:在许多硬件上,整数运算的微指令条数和指令吞吐量等可能和浮点差不多甚至比浮点差
- 访存:量化后数据传输耗时少
- 向量化技术:SIMD/SIMT,代码向量化网站
- 量化计算一般是:量化+反量化,目的是为了保证量化计算的逻辑与原来一致
量化乘法(quantized mul)
正常int8计算会溢出,所以先反量化成float计算乘法再量化,即量化计算一般要加上rescale操作
|
|
量化加法
- 加法要求两个操作数的scale必须一致
|
|
量化激活函数
- 要求输入输出的scale必须一致
|
|
量化矩阵乘(quantized Gemm)
- int8输入=》int16/32计算乘法=》int32/64保存求和结果=》量化为int8输出
量化非线性运算
- 算子包含非线性运算。如:exp、tanh、sigmoid、softmax等
- 非线性运算:用int无法替代float计算求得结果
- CPU、GPU上,不做量化,以全精度模式运行
- FPGA、ASIC、DSP上,不支持浮点运算,需要更改算子计算逻辑,以线性运算拟合或直接查表
计算图
算子
- 常见算子:https://github.com/onnx/onnx/blob/main/docs/Operators.md
- 最小调度单位
- 算子融合加速:减少访存调用栈开销,优化计算逻辑
常见计算图优化(算子融合)
计算图优化实践:https://www.bilibili.com/video/BV1Kr4y1n7cy/
- 激活函数融合:Computing Op -> Activation => ConputAct
- 常见OP:Conv、ConvTranpose、Gemm
- 常见Act:Relu、Clip(relu6)、Prelu、Tanh、Sigmoid、Switsh
- 移除batchnorm和dropout
- 常量折叠:把常量融合进行计算
- 矩阵乘融合
- conv-add融合:Conv + any => Y = Wx + (Y2 + B)
- Conv:Y1=WX+B
- any:Y2
联合定点
用于支持多后端使用,保留原始计算图信息和量化后的计算图信息
图调度(Graph Dispatching)
- 误差分析后发现部分算子的误差较大,可将其单独调度到非量化平台计算
图模式匹配
一个计算图可以表示为一个由节点、边集、输入边、输出边组成的四元组 C = {N, E, I, O}。
我们往往需要在计算图中寻找指定结构。
- 如何用一个严谨的方式定义结构?
- 如何设计计算模式匹配法,使得其尽可能高效?
- 图模式匹配是量化算法、算子融合、算子调度的基础。
- 图模式匹配可用方法:子图匹配、遍历模式匹配
例子
想象一个场景,onnx不支持swish算子,其可能用以下算子组合实现:
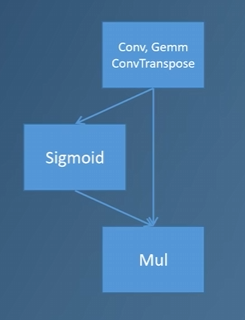 这样有一个问题,量化时会将这三个算子都量化一遍,但其实只需要量化最后一个mul算子即可。这里就可以利用图模式匹配匹配到这个替代的swish结构,并针对性进行处理。
这样有一个问题,量化时会将这三个算子都量化一遍,但其实只需要量化最后一个mul算子即可。这里就可以利用图模式匹配匹配到这个替代的swish结构,并针对性进行处理。
|
|
遍历模式匹配
- 匹配模式:起点表达式=》中继点..=》终点..,自动机
- 步骤:图拆成树,树拆成链,在每个链上进行模式匹配,期间可用动态规划优化
子图模式匹配
- 子图同构问题为NP-Hard问题,使用近似算法
- 避免模式pattern多义性,保持互斥
算子调度
- SOI正向传播:从开始算子往后找,可能有多个匹配
- 正向传播的反方向,从终点算子开始往前找
- 调度争议区:既可以量化,又不可以量化
- 调度约束:
- 激活函数与计算节点保持同一平台
- NMS、shape、TOPK、MAX与计算节点保持同一平台
- 参与图融合的算子保持同一平台
- 孤立计算节点不量化
- 多输入算子所有输入同平台
- 手动调度:权衡精度和速度,考虑硬件支持情况
神经网络部署
运行时(runtime)
实际硬件执行库,针对不同硬件有不同实现
神经网络部署
各厂商的训练框架、推理框架、硬件厂商
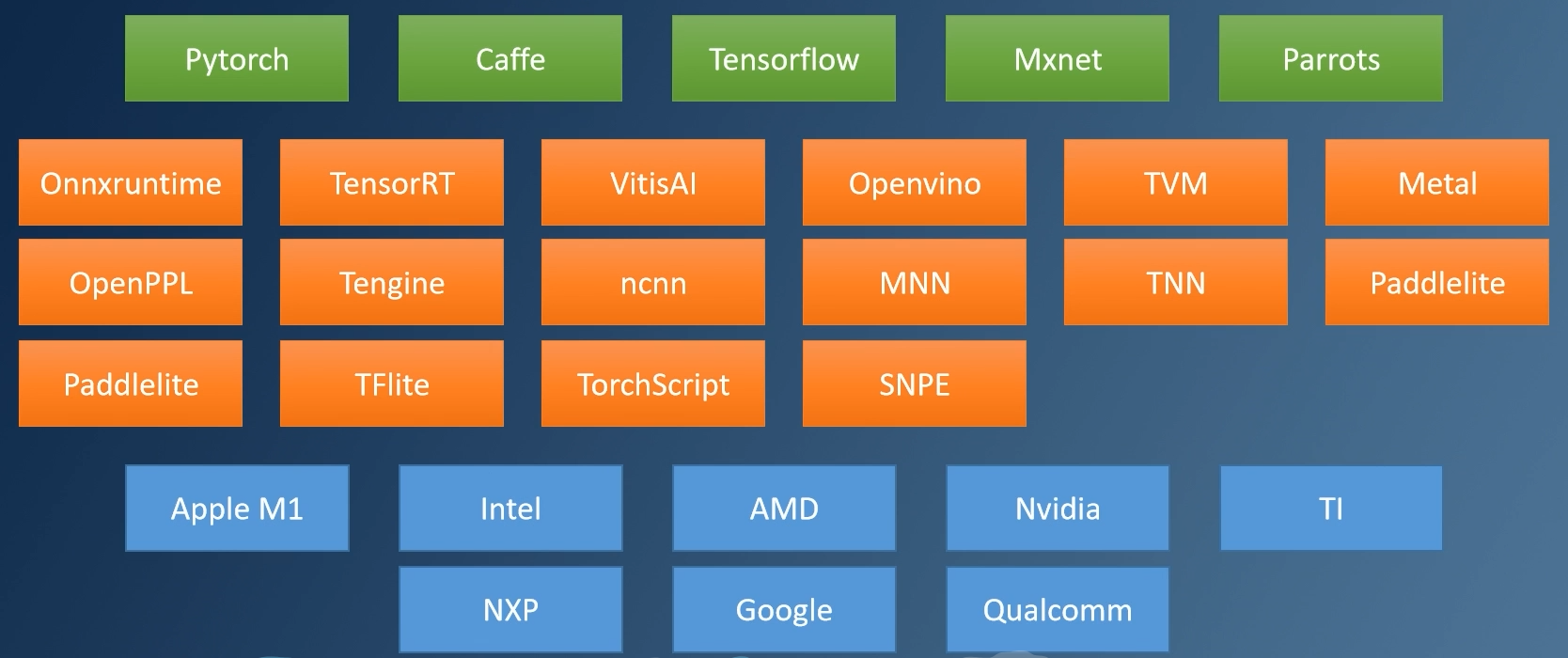
部署流程:训练框架训练模型=》导出统一中间表达模型(可选)=》指定推理框架=》指定硬件执行
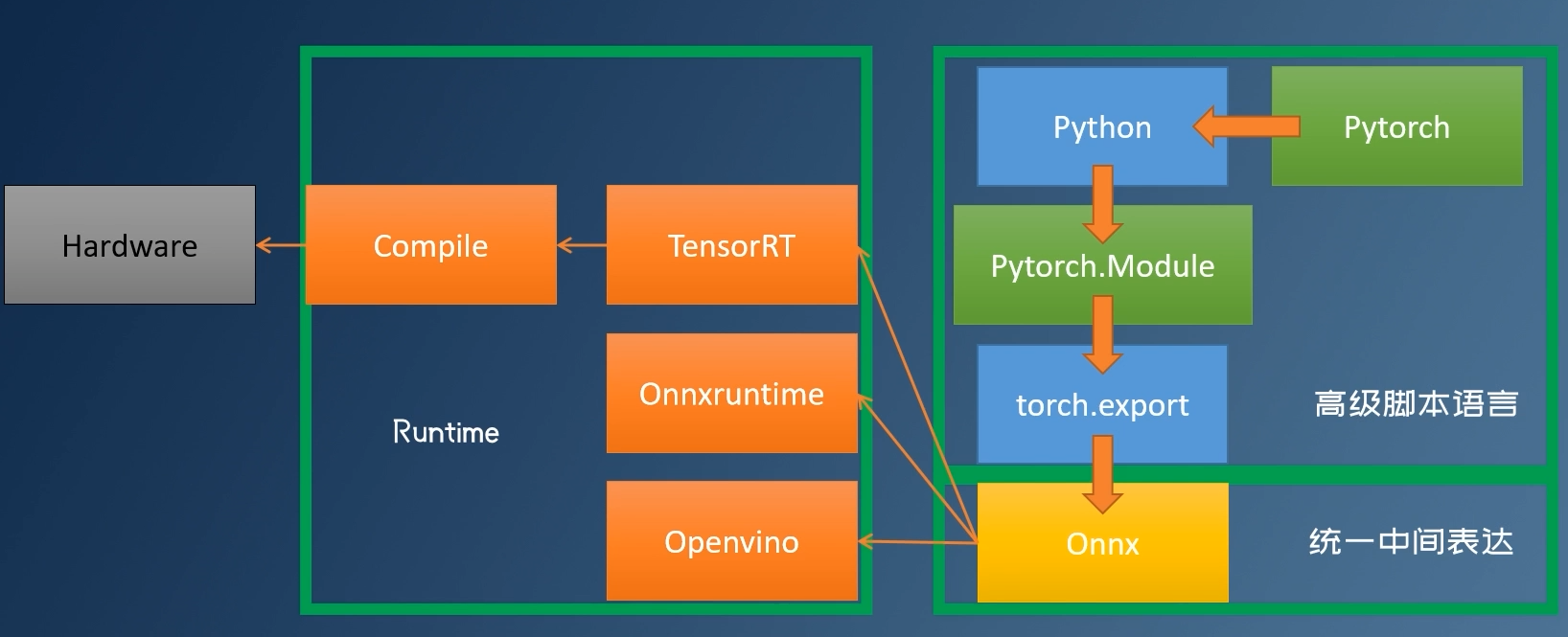
部署建议:
- 确保你的网络可以被Onnx表示,避免其中出现复杂条件逻辑及循环逻辑。
- 学会自定义算子,以备不时之需,(包括自定义算子的推理实现)。
- 避免使用各种小Trick,额外加入的算子很可能会破坏图优化。
- 神经网络能跑多快是Runtime决定的,神经网络加速应当根据runtime进行。
- 用一下 Onnx Simplifier。
- 写一个固定的 batchsize大小(latency和吞吐)。
ONNX部署推理
TensorRT
- Develop Guide, docs、quantization
- 连贯量化区:不要在网络中过度使用不可量化算子
- 网络结构设计、量化点插入不能破坏图融合
- Tensor对齐
- Profiler工具分析:Nsight System
- 自定义算子,必要时自己写plugin:https://github.com/NVIDIA/TensorRT/tree/release/10.8/plugin
量化理论分析
量化参数选择
假设

- Ln/s用比值来评估量化偏差,忽略实际值的大小
- int8实际应为-128,这里为了对称写成-127
- 注意这里的截断边界条件为.5,如127.5,-127.5,为了尽可能保留原精度
最大值截断
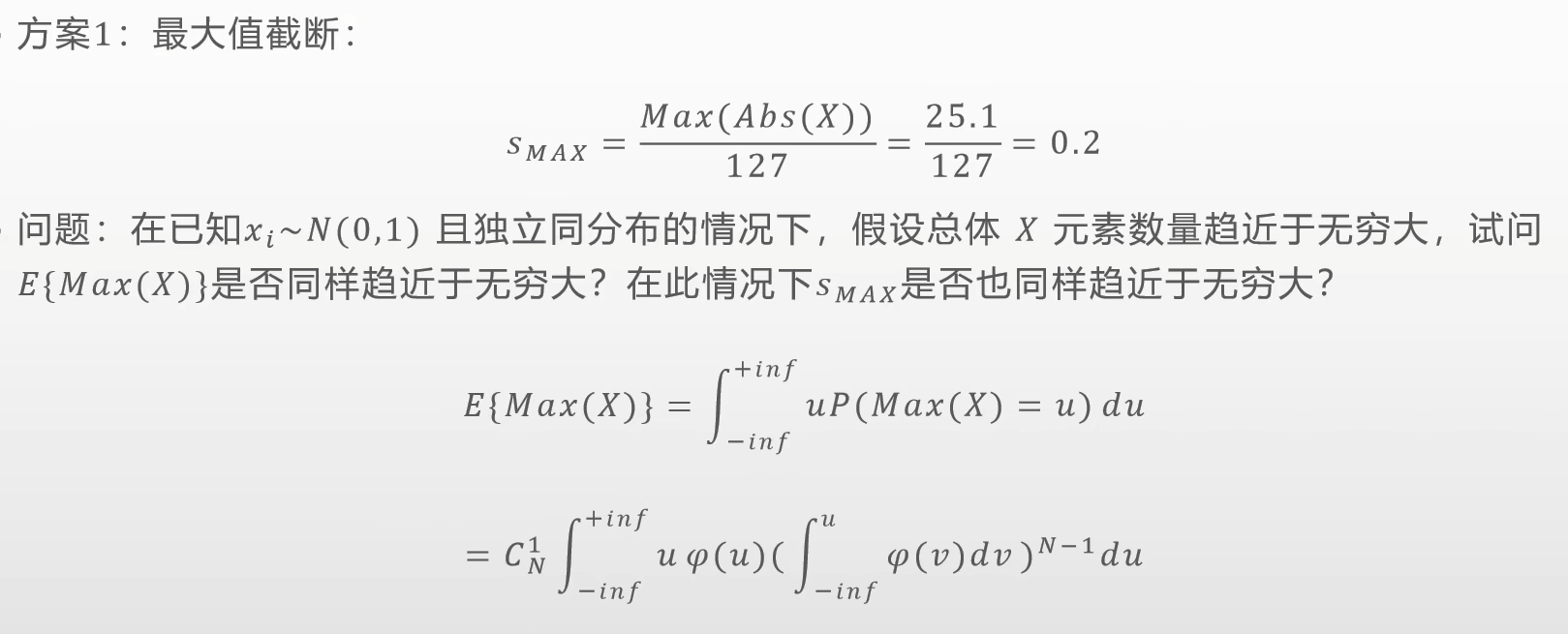
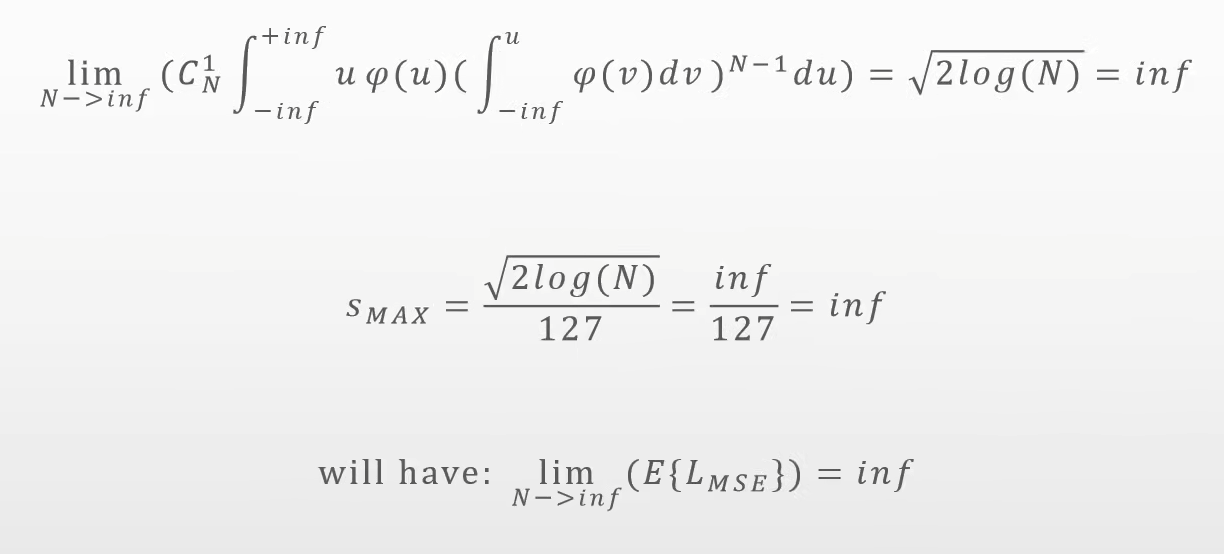
- 也就是说最大值截断在元素值趋于无限时,会出现误差发散的情况。
分位数截断
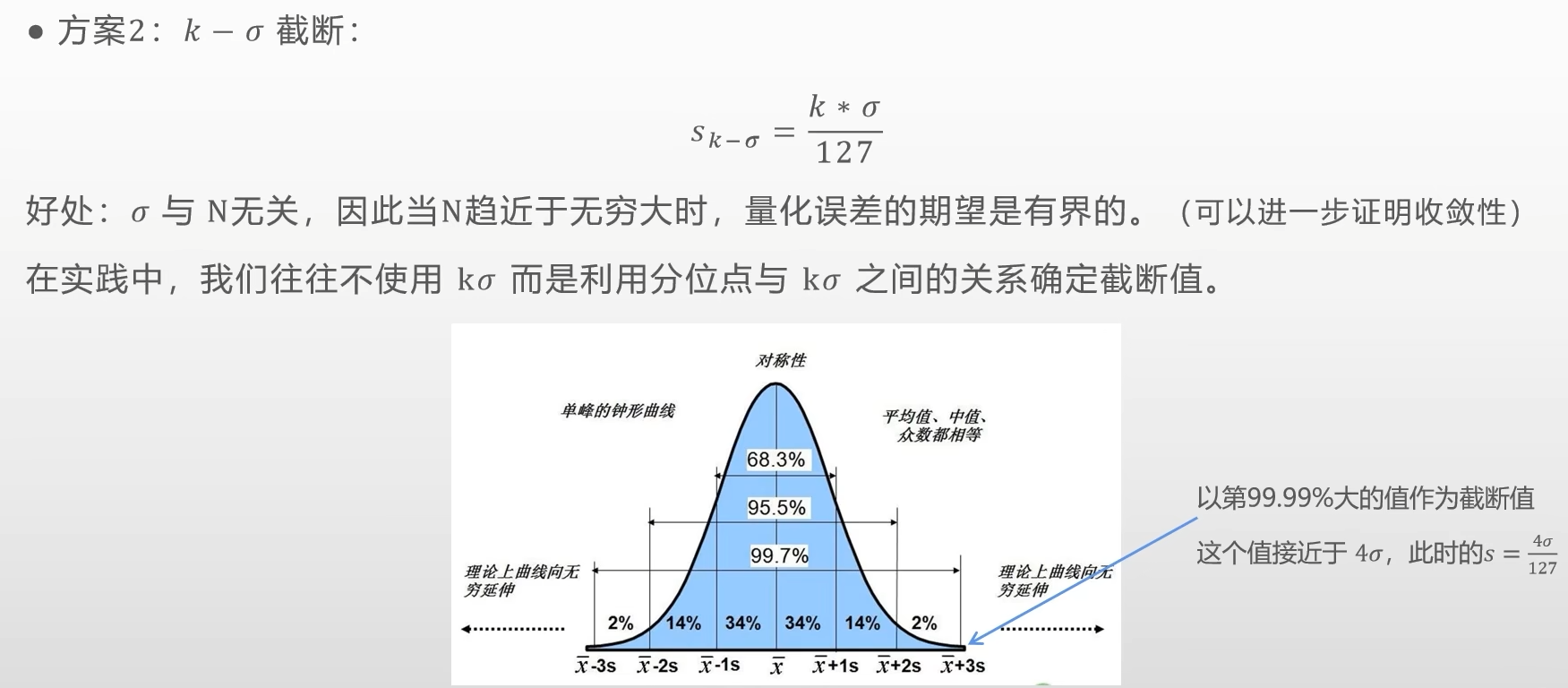
- 实际运用时,结合
3-sigma原则取近似sigma值
最优截断

Bernard Widrow公式
 最优估计问题:
最优估计问题:
- 最优截断要求pdf的三阶积分,并求导令上式为0,对于大部分分布而言,无法顺利求得解析解。
- 同时在很多情况下,局部的MSE最优并不是全局MSE最优的。
- 数据量小时,估计的方差很大。
枚举最优截断


梯度优化截断

量化误差分析
https://www.bilibili.com/video/BV1V94y117Ej/
量化框架
PPQ